$ marks the spot: saving a ton with EC2 Spot Fleet
We reduced by over 60% the EC2 instance cost of our 1000+ node globally-distributed log-producing application by migrating it entirely to EC2 Spot Fleet. We discuss some of the issues we faced and also present the log data recovery mechanism which helped enable this migration.
15-20 minute read
Background
AdRoll operates a globally-distributed real-time bidding platform running on Amazon EC2. This platform has historically used EC2 Auto Scaling in order to scale a fleet of Erlang/OTP application nodes according to load, typically exceeding 1000+ nodes (16000+ vCPUs) during times of peak volume. This article describes how we substantially reduced our EC2 costs by migrating this application entirely to EC2 Spot Fleet.
Motivation
A focus of the company has always been operational efficiency; money not spent is money earned, and reducing operating costs by $X is equivalent to earning $X / margin in additional revenue (plus the time value of money for avoided outlays).
Reserved Instances
Historically, reducing operating costs for this application has been achieved by purchasing Reserved Instances: for a partial up-front reservation, in exchange for an up-front fee per instance an hourly fee is billed per instance-hour regardless of usage. For what had until now been our application’s primary instance type, this would have worked out to savings of about 40% relative to the on-demand price.
A problem with this approach becomes apparent when considering autoscaling behavior:
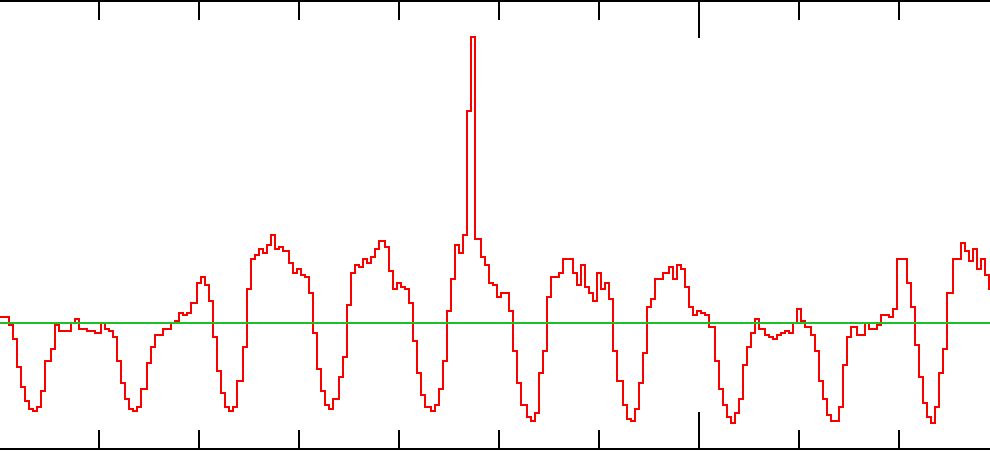
This image represents the instance count of our real-time bidding application over about a week-long period of time: the sinusoidal red line corresponds to instances running, and the horizontal green line corresponds to the median instance count over the larger window of time containing this week-long window.
How many instances should we reserve? Assuming future load will be similar to historical load, we could simply reserve the median multiplied by the expected growth factor; about half the time we’d have more instances than actually needed, and otherwise we’d not have enough and would need to purchase on-demand capacity. This would give a reasonable amount of savings, although reserving the median count isn’t necessarily optimal (and isn’t in AdRoll’s case; we use a different strategy which is outside the scope of this article).
If our future usage prediction turns out to be non-optimal, we’ll either wind up having spent too much on reservations, or too much on on-demand capacity. Making reservations for 1-year terms amplifies the cost of any misprediction since we can’t modify them after purchasing (and the reserved instance marketplace is not viable in our case).
Spot instances
EC2 Spot Instances present a relevant and compelling savings narrative: bid on market-rate capacity in exchange for an often substantial discount:
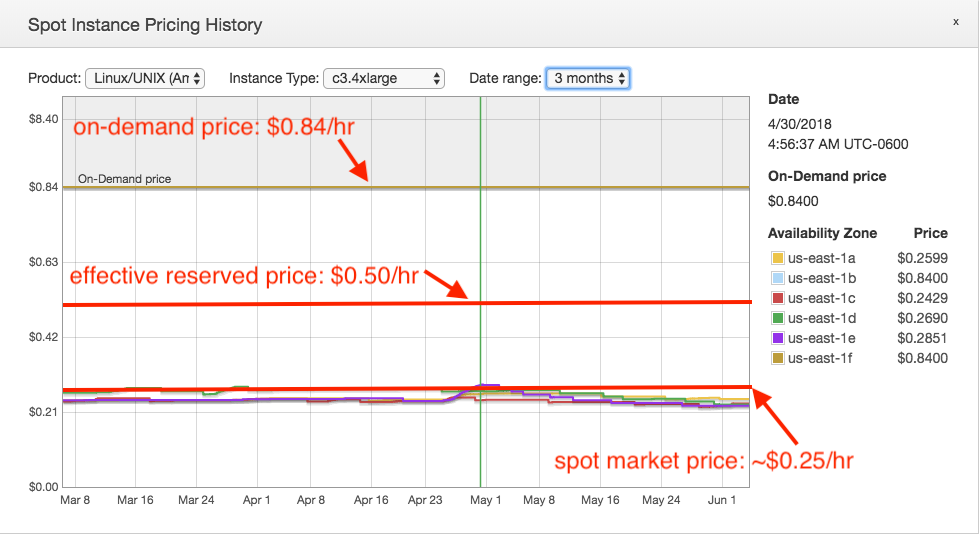
If an application can be made to use spot instances, substantial savings can ensue. In the above image, in mid-2018 the c3.4xlarge type in us-east-1 had a median spot market price of about $0.29/hr ($0.26/hr excluding outliers) – 34% of the on-demand price, and about 57% of the effective reserved price of a partial up-front reservation!
Unfortunately, these massive savings come with a massive caveat: a spot instance may be evicted at any time based on changes in market demand (i.e., when another customer has placed a higher bid during a period of high demand and low capacity in the same availability zone).
This eviction behavior relates to two problems historically preventing us from using spot instances in our application: loss of precious log data and the likelihood of occasional market capacity exhaustion.
Author’s note:
At the time this section was written, AWS had already changed its spot market behavior by making evictions randomly instead of based on bid price during periods of decreased instance availability. This means a high spot market bid no longer confers a higher chance of avoiding eviction. Our application is unaffected by this.
Problem: precious log data
Our real-time bidding application produces a large volume of log data on a daily basis: about 40TB (compressed) of logs, market data, and data used to bill customers, all written to local storage and periodically uploaded to S3.
Typical refrains here include “live with occasional data loss” or “don’t store valuable data on a spot instance”. These are unacceptable strategies for our application; we can’t afford to routinely lose portions of this dataset (and don’t want to introduce new complexity, failure modes, or cost such as by adopting Kinesis Firehose for log emission), so we can’t use spot instances without a reasonable guarantee that logs won’t be lost if an instance is evicted on short (or no) notice.
Problem: market fluctuations and capacity exhaustion
A second issue arises from the nature of the spot market: it’s possible for the market price of an instance type to rise far beyond historical levels, exceeding the effective reserved price and meeting (and at least historically exceeding) the on-demand price in that availability zone (and possibly all zones in a region). It’s also possible for capacity of an instance type to be completely exhausted in an availability zone, preventing an application from running if dependent on a specific zone or instance type.
A customer in such a situation experiences all of the drawbacks of spot usage with none of the benefits. We can’t use spot instances absent resistance to market price fluctuations and capacity exhaustion.
A viable building block: EC2 Spot Fleet
EC2 Spot Fleet appears to meet most of our requirements while granting access to spot market savings. A spot fleet allows a user to deploy spot instances without having to manage individual spot requests while also allowing use of multiple different instance types at the same time! In particular:
-
It supports autoscaling. As a result, our application could continue to scale appropriately according to load.
-
It supports multiple instance types in the same logical grouping (unlike autoscaling groups), with different spot bid prices for each type, and different allocation strategies such as “lowest price” and “diversified”. As a result, our application could gain resistance to market fluctuations and insufficient market capacity potentially affecting multiple instance types and availability zones.
-
It supports both on-demand (reserved) and spot instances in the same fleet. As a result, we have the ability to migrate our existing deployment from autoscaling groups entirely to spot fleet, simplifying operations.
Most of the time a spot instance will be given a two-minute warning before eviction; while the timing and even delivery of that notice isn’t guaranteed, it at least gives us an opportunity to gracefully stop an instance about to be evicted (though possibly without enough time to upload all of its log data, which we address in the next section).
Considering the above, it looks like we could deploy our application to EC2 Spot Fleet and treat it much the same way as we treat autoscaling groups, as long as we handle the case of eviction without having enough time to upload logs.
Implementation
The devil is in the details…
EC2 Spot Fleets are not entirely unlike Auto Scaling Groups
Up to now, we’ve been using a robust and featureful product to run our application: Auto Scaling Groups. ASGs include support for instance monitoring and health checking, various means of scaling according to load, instance lifecycle management, upgrading in-place, and discoverability & management via naming and tagging of resources.
Unfortunately, spot fleets lack feature parity with ASGs, including almost all of the above. Because we wanted to migrate our existing application with as few externally- or application-visible changes as possible, we wound up implementing our own solutions or finding alternatives for all of the following in order to present a compatible environment for running and managing our application.
Name tags
Problem
Unlike ASGs, spot fleets can’t be named or tagged. Instead, the user is presented with opaque UUIDs for created spot fleets and this user-unfriendly console for managing them:
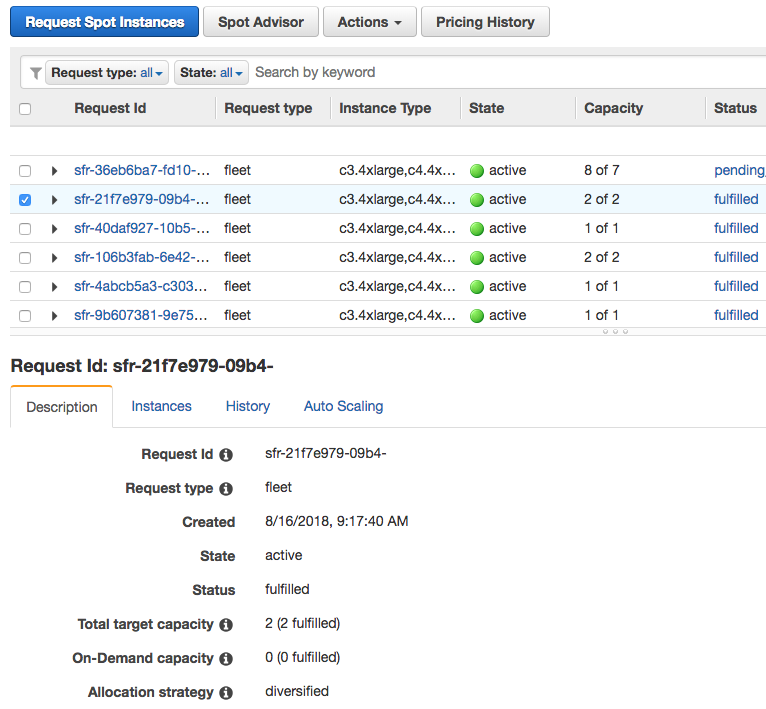
Solution
This doesn’t fit into our existing workflow, which allows custom scripts (and tools like awscli) to locate and manage resources using names and tags. The spot fleet console is also effectively useless for locating resources of interest unless a request ID is already known.
We resolved this by introducing a small DynamoDB table mapping resource names to attributes (which we would otherwise have set as tags) and spot fleet request ids, and updating our tools and workflow to reference the table.
Lifecycle hooks
Problem
Unlike ASGs, spot fleets don’t support lifecycle hooks. This feature allows instances to be kept in pending states during startup and before termination, allowing for example external resources required for operation to be created before an application starts and to be cleaned up after it exits, and for work currently in progress to be finished before termination (e.g., log uploads or active data processing):
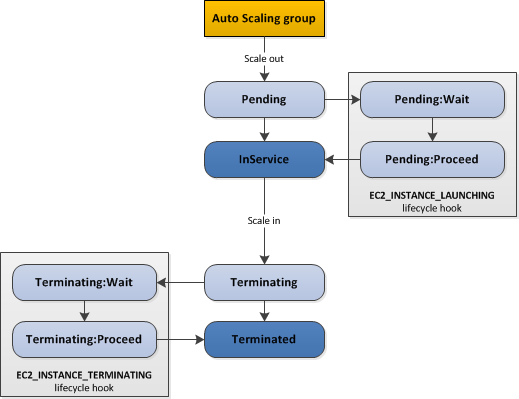
Solution
This is a feature which could perhaps be approximated for the Pending:* states by an agent running on each host and coordinating with an external resource management component. There is no substitute for the Terminating:* states (e.g., allowing an instance to upload its log data before proceeding with termination).
We resorted to simply abandoning our (limited) use of lifecycle hooks and moving the associated responsibilities into the application’s instance setup process (Pending:* states) and introducing a log recovery system as described later (Terminating:* states).
Health checks
Problem
An instance in an autoscaling group can be either in the healthy or unhealthy state. An unhealthy instance is terminated by its ASG and replaced, and an end user may set this state (e.g., from a user-operated health checker). ELBs also nicely integrate with this feature: if an application exposes a health endpoint (such as an HTTP URL), an attached ELB will set the instance as unhealthy if that endpoint fails to return a successful response.
Unfortunately, spot fleet offers no user-controllable health status; an instance will only be replaced if it fails the basic EC2 health check which has no knowledge of an application’s health. As ELBs don’t control the basic health check result, the ELB health check feature does not work with spot fleet instances.
Solution
We implemented our own health checking component using the versatile awscli tool: we run a script in a loop on a utility instance which obtains the health check configuration from each ELB (which would affect ASG instances but not fleet instances) and apply it ourselves to each attached spot fleet instance (obtained from the naming/tagging table); fleet instances older than the grace period which fail the number of checks configured in the ELB’s health check are simply terminated (as there is no user-controllable health state).
No in-place upgrading
Problem
Spot fleets use launch templates, a generalization of the launch configuration concept used in ASGs. An ASG includes a reference to its current launch configuration, which can be changed by the user without recreating the ASG. After changing the ASG’s active launch configuration, instances newly launched in the ASG adopt that new launch configuration; this allows for example the userdata of instances in an ASG to be updated, instance types to be changed, block device mappings to be updated, and so on.
Unfortunately, spot fleet has no equivalent behavior: a launch template is specified once at spot fleet request time and can’t later be changed; nor can the launch template version be changed for an existing spot fleet request (launch templates introduced a “version” concept: a launch template may have multiple versions and a “default” version, but for a spot fleet the version must be fixed in the creation request).
Solution
None; we must recreate our spot fleets whenever changing launch template parameters such as userdata, bid prices, or instance type weights and overrides.
Unexpected scaling behavior: stuck fleets
Problem
We use step scaling to scale our application according to load. This works well; each of our application instances can report its load status using a simple mechanism, and a scaling action can be taken according to the severity of the aggregate value.
In this example image, a deployment could consist of four nodes: two reporting “overload” and two reporting “stable”. In aggregate, we can say that our application is 50% overloaded and take an appropriate action (say, increasing our capacity by 25%):
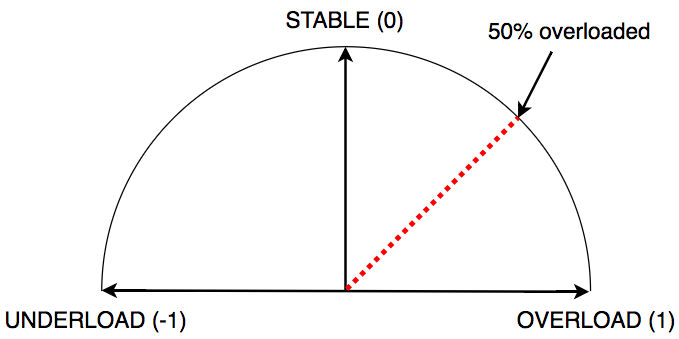
Unfortunately, this can interact poorly with how spot fleet scaling works: there are circumstances in which a user fleet can indicate scaling is required, but for which the spot fleet scaling service will take no action (visible in rounding behavior and scaling against fulfilled capacity instead of target capacity).
This is bad for our application: if we know a scaling action is required, we must always then execute such an action (or risk being unable to serve traffic and thus not earning money, or spending too much money due to having an excessive number of hosts).
Solution
We opted for a solution not requiring code or instrumentation changes in our application: a “fleet kicker”.
This component (a shell script executing awscli commands) runs in a loop on a utility instance and monitors the cloudwatch alarm state of the scaling policies associated with each of our fleets. If any alarm remains in the ALARM state for too long, the component adjusts the target capacity according to the associated scaling policy and scalable target definition.
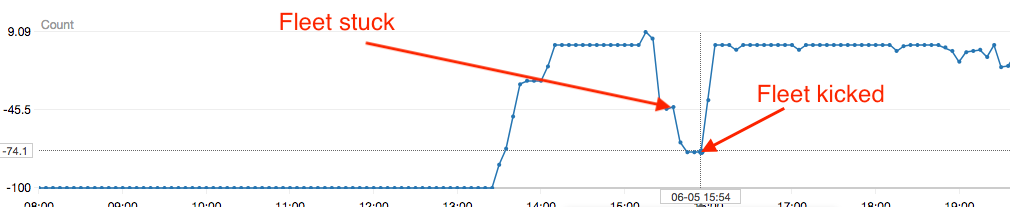
This image shows the cloudwatch metric value (multiplied by 100 to be compatible with the spot fleet UI in the AWS console) for one of our application’s fleets (negative values represent “underload”, or having too many instances relative to traffic volume). The first arrow indicates the beginning of a period in which our fleet should have scaled down, but did not. The second arrow indicates the point at which our “fleet kicker” detected the stuck fleet and activated, forcing a decrement to the fleet’s target capacity.
With this component, our fleets avoid becoming stuck and can scale up and down as we’d expect them to, and we can treat them conceptually as if they were ASGs.
[Note: AWS has indicated a possible alternate solution being switching to target tracking scaling policies, which could be useful if compatible with an application. We have not yet validated use of target tracking policies with our application.]
Spot savior: a log data recovery system
We have so far described our solutions to problems arising from attempting to treat spot fleets conceptually the same way as autoscaling groups. Our application also now makes use of many instance types in order to tolerate market fluctuations and makes appropriate bids for each type thanks to spot fleet’s override and weighting mechanic. There’s one critical piece left: what to do about inevitable spot market evictions.
Much ado about eviction
Our application stages log data to a volume attached to each instance. We periodically convey this data to S3 during normal operation, and until now also at instance termination time (previously relying on lifecycle hooks for ASG instances, which have no spot fleet analog):
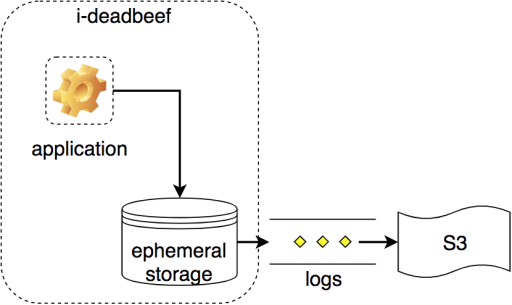
To make a long story short, we can’t guarantee that the two-minute eviction warning will be sufficient for our application when running on a spot instance:
- the warning might not actually be delivered with two minutes to spare, or at all;
- the warning could be misinterpreted due to a bug;
- the instance might have staged a disproportionate amount of log data which can’t all be uploaded to S3 in two minutes;
- adverse network or service conditions may exist, preventing timely or successful uploading to S3;
- the application might fail to gracefully stop in a timely manner, leaving insufficient time for log uploading;
and so on.
Having staged our log data, the only guarantee we can make is: our writes were acknowledged by a filesystem on some volume. What to do?
EBS to the rescue!
It turns out that Amazon EBS, a foundational network block storage product, allows block storage volumes to survive beyond the termination of the host to which they are attached.
During normal operation, we can treat an EBS volume largely the same way as an ephemeral instance store volume and stage our (append-only) logs, periodically uploading as usual:
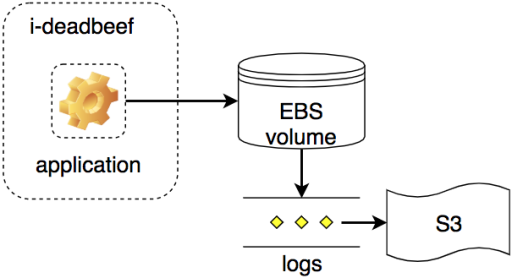
But we can also configure the volume to survive independently as an orphaned volume if its instance is terminated:
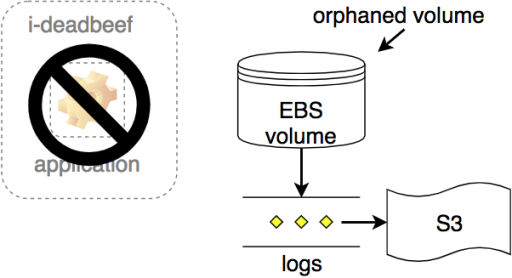
This gives us an opportunity to recover logs from evicted spot instances without having to worry about whether the two-minute warning was enough (or having to introduce a new application logging mechanism). We created a generic log recovery pipeline external to our application to do just that.
To recover logs from a volume, we need to execute a sequence of steps; each with a set of pre- and post-conditions, an implementation, and a position relative to other steps. For example: in order to copy a log file from a volume, we need to have first mounted the volume; to have mounted a volume, we need it (or a copy of it) to exist in the same availability zone as the current instance; to make a copy of a volume, we need to have created a snapshot of it (possibly using one which already exists); and so on.
There’s a ready-made tool for clearly expressing solutions to this kind of problem: Luigi.
Luigi: for connecting a series of tubes…
![]()
Luigi has been featured several times on AdRoll’s tech blog[1][2][3]: it’s a useful tool for orchestrating jobs consisting of large, dynamic, and explicit hierarchies of parameterized tasks which can depend on other tasks, any of which may fail (making any dependent tasks also fail). Even though much smaller than a typical Luigi job, this is a good fit for our log recovery scenario:
- recovering logs from an EBS volume is a batch process and insensitive to small delays and retries occurring over a period of several minutes;
- we need to recover an unknown number of logs from each volume;
- at most a single worker should be attempting recovery of a volume at any time;
- jobs are repeatable and may be incremental: each log file of interest on a volume has a 1-1 correspondence with an object on S3 (thus, we could dynamically create a Luigi task per log file and retry a failing overall job repeatedly until success);
- each recovery job has many steps, any of which may fail due to external reasons (e.g., service outages, API throttling/failures in excess of retries, unexpected worker host termination, etc).
[Aside: AWS Step Functions could also be a good fit for this scenario if a step function Lambda task could mount and access the contents of an EBS volume. Using a non-Lambda Activity worker might work, but we decided the overhead of managing a separate group of workers integrated with Step Functions would outweigh any benefit versus simply using Luigi.]
Example: Luigi volume recovery
Here’s a simplified version of our Luigi-based recovery pipeline implementation:
class RecoverLogs(luigi.wrapperTask):
volume = luigi.Parameter()
...
def requires(self):
return [UploadLogs(volume=self.volume, ...),
Cleanup(volume=self.volume, ...)]
class UploadLogs(luigi.Task):
volume = luigi.Parameter()
...
def output(self):
return luigi.contrib.s3.S3Target(
's3://bucket/%(volume)s/_SUCCESS' % dict(volume=self.volume))
def requires(self):
return {'mount': MountVolume(...)}
def run(self):
results = yield {path: RecoverOneFile(path)
for path in self.find_logs(
self.input()['mount'].read())}
self.output().write(
json.dumps({path: r.read()
for (path, r) in results.items()}))
class MountVolume(luigi.Task):
volume = luigi.Parameter()
...
def requires(self):
return {'attach': AttachAZLocalVolume(...)}
def run(self):
device = self.input()['attach'].read()
mountpoint = self.calculate_mountpoint(self.volume, device)
self.run_command(['mount', device, mountpoint])
self.output().write(mountpoint)
def complete(self):
return self.is_mounted(self.volume, self.output().read())
def on_failure(self, exc):
self.detach_and_unmount()
...
class Cleanup(luigi.Task):
volume = luigi.Parameter()
...
def requires(self):
return [UploadLogs(...), UnmountDetachVolume(...)]
def run(self):
...
yield DeleteVolume(...)In Luigi, a job is run by starting with the goal: luigi.build([RecoverLogs(volume_id, ...)]). Luigi builds a graph of task dependencies and runs each runnable task which hasn’t yet completed (each of which can dynamically introduce additional subtasks), starting from the leaves (tasks with no unmet requirements).
The end result is well-modularized and easily-testable code much like what we’d eventually arrive at after improving a non-Luigi version (but we just skipped to the end by using Luigi from the start). Here’s what a successful recovery of logs from an EBS volume looks like in our system:
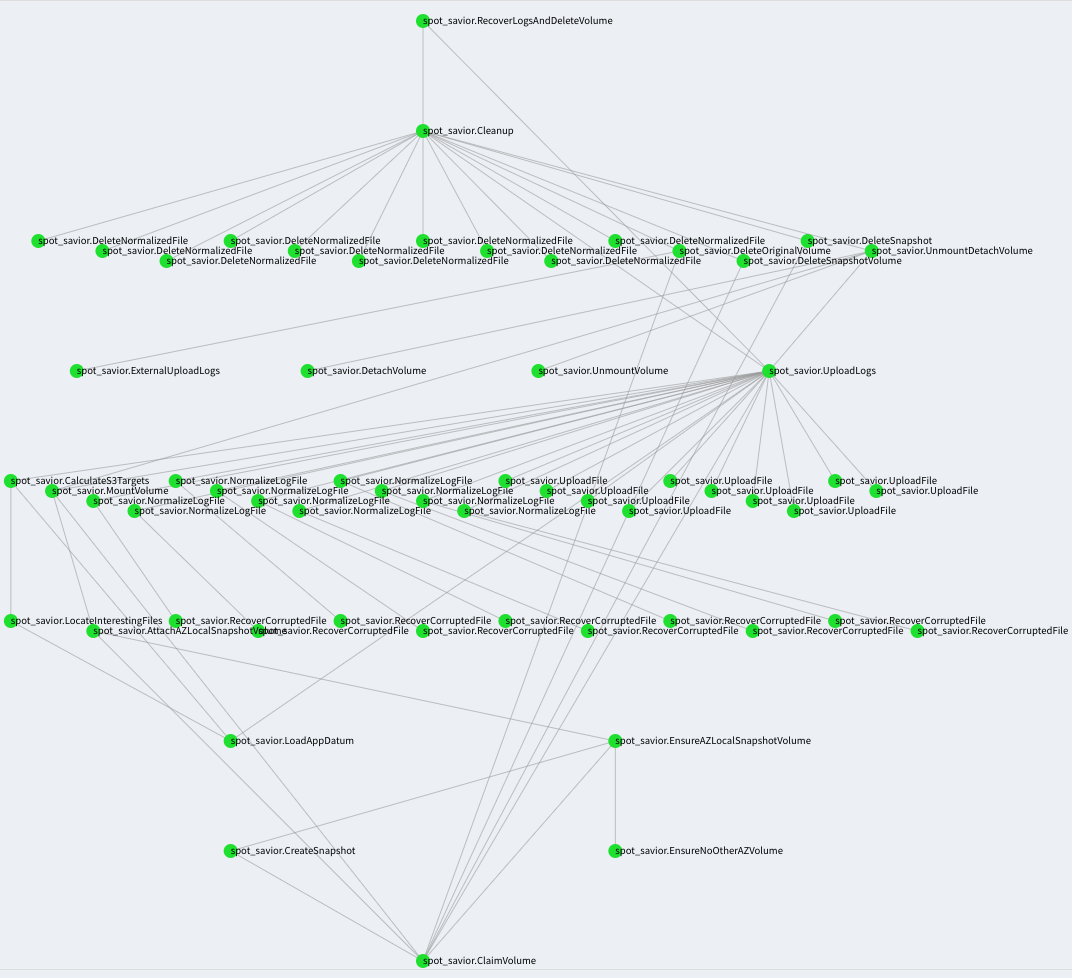
Green vertices denote successful tasks; edges express dependencies. Any failing task results in the whole job failing and being retried; but only the subtasks which haven’t yet succeeded are re-run.
Putting it all together
In practice Luigi has been a good fit for this scenario. Here’s how we put it all together:
- First, when running on a spot instance our application records log volume information in a new DynamoDB table and configures its log volume(s) as
delete-on-terminate=False, allowing them to become orphans following instance termination (such as due to a spot eviction or spot fleet scale-down event): This allows us to keep track of volumes which could actually have received any interesting application logs.
This allows us to keep track of volumes which could actually have received any interesting application logs. - Second, a recovery component executing on a utility instance periodically scans this volume information table:
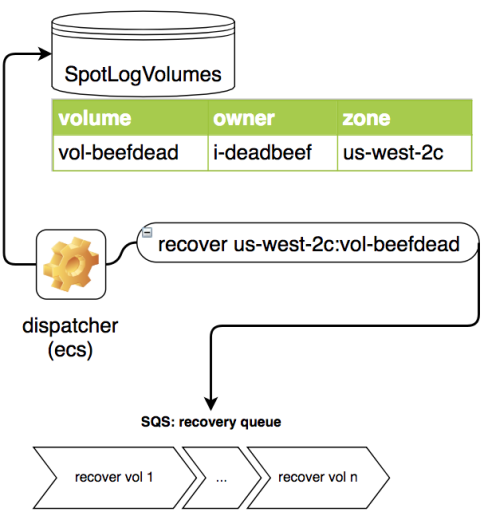 Any volume in the table in the
Any volume in the table in the availablestate is eligible for recovery, and a recovery message is dispatched to a regional queue. - Finally, an EC2 recovery worker (running in an ASG which scales according to the size of the queue) polls its regional queue for recovery messages:
 Having obtained a message, it executes the Luigi recovery pipeline for each, resulting in a volume’s logs being recovered and the volume being deleted only upon success. Naturally these workers also use spot instances!
Having obtained a message, it executes the Luigi recovery pipeline for each, resulting in a volume’s logs being recovered and the volume being deleted only upon success. Naturally these workers also use spot instances!
With a real workload, this setup can recover logs from about 650 EBS volumes per hour (in each region), largely limited by EC2 API throttling. Our implementation always makes a copy of each volume before recovery to allow filesystem journals to be replayed without modifying the original volume.
Conclusion
We modified our real-time bidding application to run on over twenty different EC2 instance types, and we’re currently using more than ten of those types in the spot fleets we created to replace our original autoscaling groups, giving a substantial amount of resistance to spot market fluctuations.
To solve the problem of precious log data being lost on terminated spot instances, we implemented a Luigi-based log recovery pipeline to recover those logs from the EBS volumes now used by our application and surviving instance termination.
As a result we’ve been able to realize substantial (~60%) savings; the effective cost of a compute unit is lower in the spot market relative to even the effective reserved instance price, and we now also no longer need to make any up-front reservations!
Uncovering and overcoming the lack of feature parity between autoscaling groups and spot fleets was time-consuming, but overall the benefits far outweigh the cost (and the savings compound over time).