Quaff that potion: saving $millions with Elixir and Erlang
We slashed our DynamoDB costs by over 75% using Kinesis, DynamoDB streams, and Erlang/OTP (and now Elixir) to implement a global cache warming system. We present that system and two new open-source libraries for processing Kinesis and DynamoDB streams in a similar way using Elixir and Erlang.
15-20 minute read
AdRoll uses Erlang/OTP as the basis for several internal products, including a real-time bidding platform running on Amazon EC2. Erlang/OTP is the king of robust highly-concurrent soft real-time systems such as these.
This article describes how we substantially reduced the cost of an element of our real-time bidding platform (its DynamoDB usage) by implementing a global cache warmer using Kinesis and DynamoDB streams, written in Erlang. We later doubled the performance of that component by adapting it to use the Flow framework from the authors of Elixir.
We also present two new open-source libraries for doing this kind of processing using Elixir and/or Erlang.
Background
Real-time bidding
When a publisher (such as a website or mobile app author) wants to monetize its inventory, it can sell ad space to buyers. This can be done using a variety of means; one of these is a programmatic auction conducted on behalf of the publisher by an advertising exchange (clearinghouse) with which the publisher is integrated, such as Google’s DoubleClick Ad Exchange or Taboola.
For most inventory, these programmatic auctions have multiple interested buyers. Much of the time, each buyer is notified by each exchange with which it is integrated whenever an opportunity to buy ad space occurs. AdRoll currently participates in well over one million programmatic auctions per second for a substantial part of each day.
In addition to supporting this high request volume, buyers must also respond quickly (typically in less than 100ms, hence “real-time”): these auctions may be occurring while a resource (web page, video, etc) is in the process of loading. A response may include a bid price, which is the maximum price that buyer is willing to pay for that particular ad space shown to a specific user. Barring any special circumstances, the highest bidder wins the auction and may display an ad in the space which was won, paying an amount determined by the dynamics of the auction (often second-price).
Ad targeting
In order to bid in an auction for ad space, a buyer needs to be able to determine how much it values a particular impression. AdRoll is able to value impressions for specific users by combining large-scale machine learning with the keeping of profiles for each of the billions of users (generally: cookies) we know about.
For web and mobile app inventory, we maintain for a period of time a set of targetable “segments” for each user who has visited an AdRoll customer’s site and who has not opted out of tracking. A segment could be something like “has visited more than N pages of the site”, “has placed an item in the shopping cart”, “has looked at brown backpacks”, “has purchased an item”, and so on. A user’s profile is the set of these segments along with timestamps and certain other information stored in DynamoDB.
The retargeting product allows an AdRoll customer to show ads to users who have previously visited their site, along with other restrictions. For example, a customer could show a “10% off brown backpacks” promotion on Thursdays and Fridays between 3 and 6 PM Pacific time to users in San Francisco who previously added them to a shopping cart but did not purchase, plus a general “5% off” promotion to similar users anywhere in California but excluding San Francisco.
AdRoll’s upper-funnel product allows customers to show ads to new “act-alike” users–users who are likely to act in similar ways as existing desirable (converting) users, but who would not otherwise be reachable via retargeting–similarly across the web and on social media such as Facebook.
When an opportunity to buy ad space presents itself, associated with that opportunity is an identifier for the user who would see our customer’s ad if we won the auction. Using that identifier, we can look up the user’s profile data and find the ads which are relevant, and then with advanced machine learning models price in real time a set of possible bids using those ads.
Profile data system overview
As described above, DynamoDB is the effective source of truth for our advertising profile data; this works very well.
Unfortunately, it’s also very expensive: in order to meet our low-latency requirement, we need to replicate our profile data globally in each AWS region where we operate (and due to some design constraints we could not limit replication to a subset of profile data). Under this scheme our DynamoDB costs, dominated by write capacity costs, are multiplied by the number of regions we use.
Original design
To access this profile data from our bidding system we initially implemented a straightforward setup like the following, replicated globally. From our application’s perspective, this works like a read-through cache:

In this diagram, boxes on the left represent user profile updates which occur constantly throughout the day. The updates are written to various DynamoDB tables in every region by separate data processing pipelines. When a bidder instance seeks to obtain a user’s profile, it checks its local caches before reading from DynamoDB. If recent cached data is found, it is used; otherwise, the instance reads from DynamoDB and then caches the data for next time.
As described below, we eventually created a similar system allowing the removal of most usage of DynamoDB from all but one region, cutting our DynamoDB costs by a very large degree.
New design
While DynamoDB is our bidding system’s source of truth for profile data, we found that we don’t actually need to read it most of the time: most data for users of interest can be made to reside in cache by increasing the cached item TTL. Of course, doing that alone would lead to stale data and inaccurate user targeting and bid pricing. If we could have long-lived cache data for most users which is also kept up to date, we wouldn’t need to consult DynamoDB most of the time.
We devised a solution to support just that: a set of large(r) caches exists in each region, and each region constantly receives updates–up to 500,000/sec depending on time-of-day–made on a set of master tables in a single region. Kinesis and DynamoDB streams were the natural choices for this workload:
DynamoDB stream aggregator
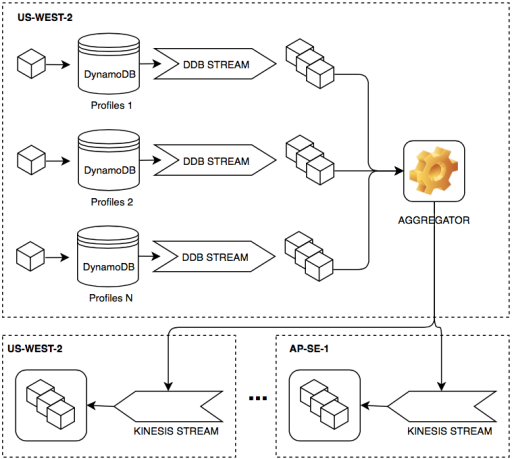
Here, a data-agnostic aggregator component observes updates as they occur on the set of relevant DynamoDB streams. It batches these updates together and replicates them to Kinesis streams in all target regions which formerly had the same DynamoDB tables as the master region.
Kinesis stream processor
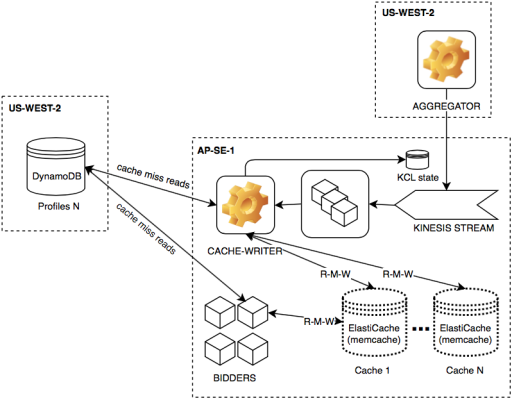
In each target region operates a Kinesis stream reader (and cache writer) component which updates long-lived items in a set of caches. Both it and our real-time bidding system fall back to reading from tables in the master region (a relatively slow but rare operation) when data is missing from the cache or is incomplete, writing it back to the local cache using a CAS operation to ensure consistency.
This allowed us to keep the same conceptual design for the multiple involved systems while still realizing substantial savings: we can tolerate a slower source of truth if most data is accurately cached and long-lived, which is now the case.
Implementation
Chief among our concerns in designing this system were correctness (if we have bad data, we can’t make good bidding decisions), robustness (if the system is down, we’ll have bad or missing data), and scalability (we need to handle an arbitrary volume of data). Secondarily, speed was also a consideration. After a successful (but not very scalable) proof-of-concept which used Python, we elected to implement the complete solution using Erlang, building on our expertise in this area while also being a good fit in general for this type of problem.
On scalability
The essence of scalability is being able to efficiently apply a repeatable formula to an arbitrary load. In the realm of software systems, Erlang/OTP makes this easy: with a set of robust building blocks (OTP), systems comprised of shared-almost-nothing sequential blocking processes can easily be created–and more importantly their behavior can be easily understood. Process independence enables arbitrary horizontal scaling. Contrast for example with a deferred/promises or asynchronous callbacks model more common in other environments with more cumbersome concurrency, or shared-state threads which bring their own issues.
On robustness
Erlang/OTP promotes robust system designs. “Let it crash” and supervision trees makes for simple-to-understand control flow and process behavior. A process is always part of a greater whole, and will “do stuff until it can’t”, then crash & burn knowing it’s part of a system which was designed from the ground up with appropriate failure modes. If appropriate, such failing processes may be restarted by a supervisor somewhere in the system to try again.
On correctness
Erlang’s syntax and design promotes the succinct and functional expression of programs and avoids unnecessary defensive programming. Less code written means less code to be read and understood later, and fewer places for bugs to hide.
But enough about Erlang; enter…Java?
To ensure the correct ordered processing of data and abstract away the handling of details like work distribution and instance failure, we elected to use the existing Java-based Kinesis Client Library provided by Amazon. The KCL provides a JSON-based language-agnostic interface (MultiLangDaemon) which allows Kinesis processing (and DynamoDB streams processing using an adapter) to be done in any language and environment without writing any Java code.
Unfortunately, the KCL/MultiLangDaemon expects to be the driver of any resulting processing system: it emits events to which the processor reacts and launches one processor executable per owned stream shard to effect that processing. While this makes for very simple processing code, we need to efficiently process up to thousands of shards across multiple streams, and launching thousands of BEAM nodes to do that would be wasteful (and partly defeat the purpose of using Erlang). We also wanted to manage the KCL processes themselves.
Erlang MultiLangDaemon interface
Erlang systems are pretty good at being network servers, so we turned this problem around by creating an adapter which launches a MultiLangDaemon whose worker subprocesses become lightweight network clients of our Erlang node:
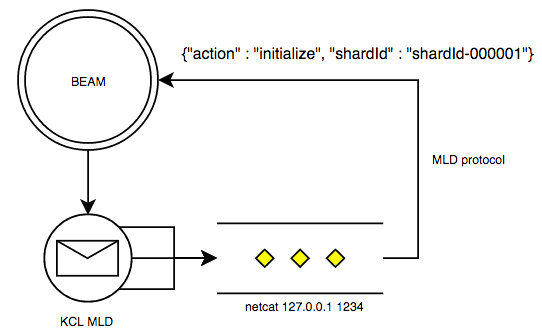
For each stream being processed, our Erlang node launches a MultiLangDaemon subprocess as a port program. Each such subprocess is configured to launch a netcat-like program (socat) as a shard processing program, which simply maps stdin/stdout back to the port on which the node is listening for that MLD’s stream.
Thus, each owned shard is mapped to an independent Erlang process (a gen_statem state machine) in a single node, and each such process is only concerned with handling a single stream record at a time (and deciding when to periodically checkpoint). The result looks like this:
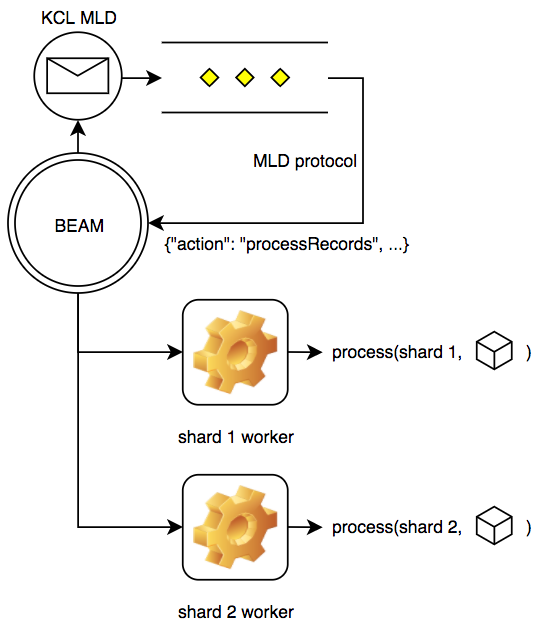
This gives most of the benefits of using the KCL and results in a processing application which is similar to how Java-based KCL processing applications work (multiple threads of execution within a single VM), but without requiring the user to write any Java code. It allows for very simple shard processors like this minimal example:
-module(noisy_worker).
-behavior(erlmld_worker).
-export([initialize/3,
ready/1,
process_record/2,
shutdown/2]).
-include_lib("erlmld/include/erlmld.hrl").
-record(state, {shard_id, count = 0}).
initialize(_Opaque, ShardId, ISN) ->
State = #state{shard_id = ShardId},
io:format("~p initialized for shard ~p at ~p~n",
[self(), ShardId, ISN]),
{ok, State}.
ready(State) ->
{ok, State}.
process_record(#state{shard_id = ShardId, count = Count} = State,
#stream_record{sequence_number = SN} = Record) ->
io:format("~p (~p) got record ~p~n", [ShardId, Count, Record]),
case Count >= 10 of
true ->
{ok, State#state{count = 0},
#checkpoint{sequence_number = SN}};
false ->
{ok, State#state{count = Count + 1}}
end.
shutdown(#state{shard_id = ShardId, count = Count}, Reason) ->
io:format("~p (~p) shutting down, reason: ~p~n",
[ShardId, Count, Reason]),
case Reason of
terminate ->
{ok, #checkpoint{}};
_ ->
ok
end.New open-source library: erlmld
We created an open-source Erlang library for Kinesis and DynamoDB streams processing (erlmld) using MultiLangDaemon.
It also includes support for compressed KPL-style record aggregation and an additional behavior which turned out to be a common pattern in our own usage of the library: accumulating batches of records and flushing them periodically or when “full”. This allows even simpler shard processor definitions:
-module(noisy_flusher).
-behavior(erlmld_flusher).
-export([init/2,
add_record/3,
flush/2]).
-include_lib("erlmld/include/erlmld.hrl").
-record(state, {shard_id, buf = []}).
init(ShardId, _Opaque) ->
#state{shard_id = ShardId}.
add_record(#state{buf = Buf}, _, _) when length(Buf) >= 10 ->
{error, full};
add_record(#state{buf = Buf} = State, Record, Token) ->
{ok, State#state{buf = [{Token, Record} | Buf]}}.
flush(#state{shard_id = ShardId, buf = Buf} = State, _Kind) ->
{ProcessedTokens, Records} = lists:unzip(Buf),
io:format("~p processing batch: ~p~n", [ShardId, Records]),
timer:sleep(1000),
NState = State#state{buf = []},
{ok, NState, ProcessedTokens}.Here, a processor builds a batch of records to be processed. A backpressure mechanism exists to ensure records are supplied only as fast as the processor can handle: if a batch is full, the processor is instructed to flush (i.e., perform a batch of work), which can take an arbitrary amount of time.
After flushing, the processor returns the opaque tokens corresponding to each successfully-processed record, which allows the system to periodically checkpoint only up to the highest contiguous completed record on the stream. If a worker dies or a new one comes online and steals a lease, some work might be repeated but none will be lost.
Beyond Good and Erlang
The arrangement described above is scalable and works well, but the process-per-owned-shard model means our concurrency is limited by the number of stream shards. If we have a processing system with 16 cores and we’re processing a stream with 8 shards, at least half of our computing resources are wasted unless we take special measures which make our simple processing code be not so simple.
For our use case, it turns out we can scale our processing independently of stream shards while preserving approximate (ordered by cookie) in-order processing and simple processing code, which is especially helpful for I/O-bound tasks like ours.
New open-source library: exmld
We created an open-source Elixir library for Kinesis and DynamoDB streams processing (exmld) which builds on our Erlang library erlmld. It can be used in both Elixir and Erlang-based processing systems.
It makes use of the Flow framework to set up a MapReduce-style processing pipeline inside BEAM: instead of having a set of worker processes which each handle a single shard, data from all shards owned by the current node feeds into a pipeline which sends data downstream to a set of reducers of arbitrary number. Each reducer consistently handles a partition of the key space (i.e., record keys are hashed and distributed among reducers, and the same reducer will always receive records having the same key in approximate order).
Here’s what we had before with the Erlang-based system:
And here’s what we now have with the Elixir Flow-based processing pipeline:
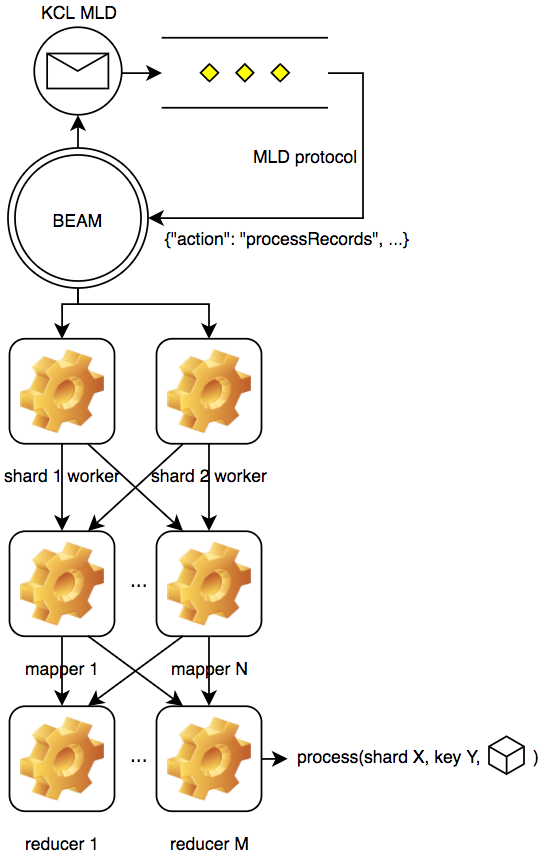
Here, using the Flow framework, our shard workers no longer directly process records. Instead, they feed records into a set of mappers which extract zero or more items to be processed from each. Each of these items has an associated key which is used to distribute them among a set of reducers, which do the actual processing work. As work is completed, the workers which originated each record are notified so they can checkpoint and make progress on the shard they own.
This configuration allows re-use of any existing processing code with minor modifications, but with greatly increased concurrency which is unrelated to the number of stream shards owned by the current node (we can use an arbitrary number of mappers and reducers). It helps us because we have an I/O bound task where processing can occur independently for each cookie which is seen; ordering of events is generally preserved for single cookies within a single worker (but not between different cookies).
Elixir+Erlang sample processing code
Here’s a complete example of using Erlang processing code with this new Elixir library. The “disposition” concept is used to keep track of the status of event processing to support stream checkpointing and provide backpressure; see exmld docs for details. In a real application, an actual supervision tree would be used. The same organization of code would also apply to an Elixir processing application using this library.
-module(exmld_example).
-export([start/0]).
-record(state, {count = 0}).
-include_lib("erlmld/include/erlmld.hrl").
%% this will result in calls to process_event/2 for items extracted from
%% records seen on `StreamName` in `StreamRegion`. run
%% erlmld/priv/download.sh before running this to download needed JARs.
start() ->
StreamRegion = "us-east-1",
%% this affects kcl state table name:
AppName = "your-erlang-kcl-application",
StreamName = "your-stream-name",
{ok, Stage} = 'Elixir.Exmld.KinesisStage':start_link([]),
FlowSpec = #{stages => [Stage],
extract_items_fn => fun extract_items/1,
%% use first extracted item element as a reducer
%% partition key:
partition_key => {elem, 0},
state0 => fun () -> #state{} end,
process_fn => fun process_event/2,
flow_opts => []},
{ok, FlowWorker} = 'Elixir.Exmld':start_link(FlowSpec),
ProducerConfig = #{record_processor => erlmld_batch_processor,
record_processor_data =>
#{flusher_mod => 'Elixir.Exmld.KinesisWorker',
flusher_mod_data => [{stages, [Stage]}],
flush_interval_ms => 10000,
checkpoint_interval_ms => 60000,
watchdog_timeout_ms => 600000,
description => {StreamName, StreamRegion},
on_checkpoint => fun on_checkpoint/2},
kcl_appname => AppName,
stream_name => StreamName,
stream_region => StreamRegion,
stream_type => kinesis,
%% these would normally be set via app env:
listen_ip => loopback,
listen_port => 0,
app_suffix => undefined,
initial_position => <<"LATEST">>,
idle_time => 1000,
metrics_level => <<"SUMMARY">>,
metrics_dimensions => <<"Operation">>,
failover_time => 10000,
ignore_unexpected_child_shards => false,
worker_id => undefined,
max_records => 1000,
max_lease_theft => 1,
shard_sync_time => 60000},
{ok, ProducerSup} = erlmld_sup:start_link(ProducerConfig),
{ok, [Stage, FlowWorker, ProducerSup]}.
on_checkpoint(Description, ShardId) ->
io:format("~p checkpointed on ~p~n", [Description, ShardId]).
%% this function should normally return a list of items to be processed
%% by process_event/2. if records are using the KPL-style aggregation
%% supported by erlmld, this can just return single-element lists. due
%% to the definition of 'partition_key' above, this should return
%% 2-tuples where the first element is a partition key to use in
%% distributing work among reducers. this example just uses the
%% record's partition key.
extract_items(#{'__struct__' := 'Elixir.Exmld.KinesisStage.Event',
stage := Stage,
worker := Worker,
event :=
#{'__struct__' := 'Elixir.Exmld.KinesisWorker.Datum',
stream_record := R}}) ->
Value = case R of
{heartbeat, X} ->
{X, heartbeat};
#stream_record{partition_key = K} ->
{K, {Stage, Worker, R}}
end,
[Value].
%% this function is used as a Flow reducer. it accepts an extracted
%% item and a reducer state, and returns an updated state after doing
%% any needed processing.
process_event({Key, Value}, #state{count = C} = State) ->
case Value of
{Stage, Worker, #stream_record{sequence_number = SN}} ->
%% notify upstream stage of disposition of processing so the
%% originating worker can make progress and checkpoint. in a
%% real application this would be done in batches after work is
%% completed, and the status would vary based on processing
%% outcome.
WorkerMap =
#{Worker =>
[#{'__struct__' => 'Elixir.Exmld.KinesisWorker.Disposition',
sequence_number => SN,
status => ok}]},
ok = 'Elixir.Exmld.KinesisStage':disposition(Stage, WorkerMap),
%% do some work and return updated state:
io:format("~p processing ~p (seen: ~p)~n", [self(), Key, C]),
timer:sleep(100),
State#state{count = C + 1};
heartbeat ->
%% heartbeats are used to prevent stalls when a worker is
%% waiting for processing to happen and dispositions to be
%% returned.
io:format("~p ignoring heartbeat event~n", [self()]),
State
end.Impact
Using this new arrangement with our existing Erlang code, we doubled the performance of our system. Here’s a snapshot of what happened to our stream delay metric after we deployed an Elixir Flow-using version of our application following a service degradation:
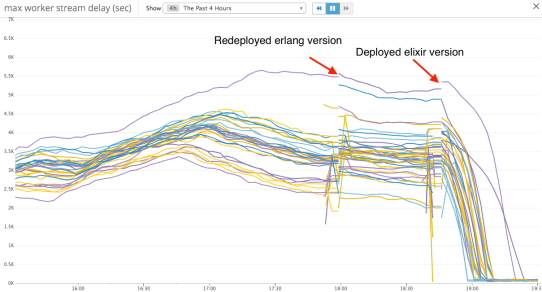
Here, the Erlang-only system had fallen behind and entered an unhealthy “far behind tip of stream” state. It had scaled up to the maximum size and was recovering, but not very quickly. The Elixir-using version was deployed to gauge performance during recovery; stream processing delay fell off a cliff, and this Elixir-using version has been running since.
Conclusion
Using Erlang and now Elixir, we were able to implement a scalable system which cut our DynamoDB costs by over 75%. Using some Elixir glue code[2] enabling use of the Flow framework, we doubled the performance of our previously Erlang-only system with only minor modifications. We also open-sourced[1][2] the code we’re using to process high-volume Kinesis and DynamoDB streams data in Erlang and Elixir.
I enjoyed working on this system, and Elixir is now firmly in our toolbox for use in the future!
[1]: https://github.com/AdRoll/erlmld
[2]: https://github.com/AdRoll/exmld
Do you enjoy working with large-scale systems? Roll with Us!