Running large batch processing pipelines on AWS Batch
The attribution team at AdRoll computes metrics out of petabytes of data every night. This is accomplished using a batch processing pipeline that submits jobs to AWS Batch. In this blog post we discuss how this is organized and orchestrated with Luigi. We announce Batchiepatchie, a job monitoring tool for AWS Batch. Batchiepatchie is an improvement over Amazon’s own monitoring solution for AWS Batch and it has saved us countless hours of engineer time.
10-15 minute read
To start off, we have open sourced Batchiepatchie that is discussed in this blog post. Read on to understand what this piece of technology is!
Before we delve into technicals of batch processing, I want to establish some real world context. Our batch pipeline was created for the purpose of doing something called attribution in Internet advertising. What is attribution, in adtech sense? To put it very simply, it is the problem of figuring out which advertising events deserve credit when people purchase things. For example, if we show an advertisement to a person about a T-shirt and one day later they buy said T-shirt, we can say that advertisement impression deserves some credit for making that purchase happen. Attribution is used to understand how some advertising campaign is working out.
The problem of how much credit should be given and in which circumstances and how to report on it is a complicated topic and is a story for another time. This post is about the batch job infrastructure that can compute metrics around this problem by making use of vast amounts of data.
To compute attribution metrics, we need to be able to look at the history of all event trails of each user we track. An event trail contains all the relevant information of each user for attribution purposes, such as when we displayed advertisement from certain advertising campaigns and when purchases were made on a customer’s website. From this information, we can compute how much credit each advertising campaign deserves.
At AdRoll’s scale, this is a non-trivial amount of data. All the attribution metrics must be computed on a daily basis. Even a big EC2 instance cannot process all of it in a reasonable time; just downloading all the required data in compressed format would take too long with a single box. Thus, we must distribute the problem to many computers. This is where AWS Batch comes in.
AWS Batch
So what is AWS Batch anyway? You can read the official description at Amazon’s website but for our purposes it can be described as follows.
AWS Batch is a system that you submit jobs into. AWS Batch runs these jobs on EC2 instances. AWS Batch scales up a bunch of instances as needed so that the jobs can run. Once all the jobs are done, the instances are put down. This way, you will pay for instances only when you actually have some jobs running. These days AWS has per-second billing of EC2 instances , which makes fast scaling a critical feature in terms of minimizing your AWS bill.
Another way to describe this process is that you give AWS Batch a Docker image URL, some command line arguments and CPU and memory requirements and AWS Batch will figure out how to run your job in some way.
AWS Batch is a relatively simple way to distribute large amounts of batch jobs onto lots of EC2 instances and in a way that you only pay when you actually have jobs running.
Example of a batch job pipeline
So, how do you use the AWS Batch system to split off your massive batch processing so that bunch of boxes will run your job instead of just one box? I thought one of the most illustrative ways to describe how our system works is to show a representative example of actual technologies we use to do this.
The most important technologies involved with this process is Amazon S3, Docker and Luigi and our internal (but now open sourced!) AWS Batch dashboard called “Batchiepatchie”.
Luigi
At AdRoll’s attribution team we use a Python library called Luigi to orchestrate tasks. We have talked about Luigi before in our blog so you can read our older blog post for some more background on that topic; most of it is still relevant for this Luigi section, although we use a slightly different set of technologies than we did back in 2015.
Let’s say that hypothetically (or not so hypothetically, this example is a simplified version of a real-world job) we want to compute the last click credit on advertising campaigns using TrailDBs as our source of data.
We have TrailDB files in S3 in an organized directory structure, where each day has its own set of TrailDBs. For example, we have a type of attribution TrailDB that contains data relevant for attribution purposes.
$ aws s3 ls s3://example-bucket/traildbs/attributiondb/2018-07-26/
2018-07-27 18:24:03 attributiondb-0.tdb
2018-07-27 18:24:39 attributiondb-1.tdb
2018-07-27 18:25:07 attributiondb-2.tdb
2018-07-27 18:23:38 attributiondb-3.tdb
2018-07-27 18:18:41 attributiondb-4.tdb
2018-07-27 18:55:22 attributiondb-5.tdb
2018-07-27 18:36:03 attributiondb-6.tdb
2018-07-27 18:10:10 attributiondb-7.tdb
In the above example, we have 8 files. These files contain all data for that particular day; in this example, that day is 2018-07-26.
This naturally distributes to at least 8 workers: just submit one batch job per file. One worker processes one file.
We will look at how to do this with some Luigi, S3 and AWS Batch.
# lastclick.py
import luigi.s3
import luigi
class AttributionLastClickJob(luigi.WrapperTask):
date = luigi.DateParameter()
s3_input_prefix = luigi.Parameter()
s3_output_prefix = luigi.Parameter()
shards = luigi.IntParameter()
def requires(self):
sub_jobs = []
for shard in range(self.shards):
sub_jobs.append(AttributionLastClickShard(
date=self.date,
s3_input_prefix=self.s3_input_prefix,
s3_output_prefix=self.s3_output_prefix,
shard=shard))
yield sub_jobs
Let us first go through what is happening in this file. We have four arguments to our task, date, input prefix, output prefix and shards. These specify the date we are processing, an S3 input prefix where our input data is located, an S3 output prefix where we should put output data and the number of shards we have (in this example, shards is 8).
For this example, we could have, date=2018-07-26, s3_input_prefix=s3://example-bucket/traildb/attributiondb, s3_output_prefix=s3://example-bucket/attribution-results and shards=8.
This particular Luigi task is a wrapper task which means it does not run jobs by itself, it only requires other tasks and those other tasks do the actual work. AttributionLastClickJob wants to distribute the 8 input shards into 8 batch jobs. We collect each job shard into sub_jobs list. When we do yield sub_jobs, Luigi will concurrently run all the jobs listed in sub_jobs list.
The task class above refers to something called AttributionLastClickShard. Here is the source code for that:
# lastclick.py - continued
import os
import pybatch
class AttributionLastClickShard(luigi.Task):
date = luigi.DateParameter()
s3_input_prefix = luigi.Parameter()
s3_output_prefix = luigi.Parameter()
shard = luigi.IntParameter()
def output(self):
return luigi.s3.S3Target(
os.path.join(self.s3_output_prefix,
self.date.strftime("%Y-%m-%d"),
"output.{}.sqlite3".format(self.shard)))
def run(self):
cmdline = [
"do_lastclick_attribution.py",
"--input-prefix", self.s3_input_prefix,
"--output-prefix", self.s3_output_prefix,
"--shard", self.shard
]
pybatch.run_on_awsbatch(container='attribution:1.0',
cmdline=cmdline,
cpus=16,
memory=110000,
jobqueue='attribution-job-queue')
if __name__ == '__main__':
luigi.run()
This is where submitting the job to AWS Batch happens. In the output() method, we define what result this job will ultimately create; in this example, it is an SQLite file in S3.
In run() method, we define a command line that runs a Python script do_lastclick_attribution.py. This command line is passed to AWS Batch and it describes the command line arguments we pass to a Docker container when AWS Batch runs it.
The call pybatch.run_on_awsbatch actually submits the job to AWS Batch. This is an AdRoll-internal job submitting function that knows about AdRoll infrastructure and simplifies the submission process. In your application, dear reader, you would likely use boto Python libraries to do this.
This function will only return when the job has completed successfully. If the job fails, then run_on_awsbatch will throw an exception.
Running this job is not difficult. Just invoke the script with some arguments:
$ chmod +x lastclick.py
$ ./lastclick.py --date 2018-07-26 \
--s3-input-prefix s3://example-bucket/traildbs/attributiondbs \
--s3-output-prefix s3://example-bucket/attributions \
--shards 8 \
--workers 8
This will invoke our distributed job, with Luigi handling concurrent submission to AWS Batch.
Most of our real batch jobs have been set up in this manner. There are some additional complexities with our real systems I did not elaborate on in this example, such as:
-
We have an automatic crontab generator that will set up a scheduling box based on Luigi task files in a git repository. It will (try to) run all jobs every 5 minutes. We rely on Luigi to stop duplicate jobs from running and stopping any jobs that have already completed.
-
All jobs have been designed to be idempotent. If some job fails then we can safely resubmit it.
-
AWS Batch wants you to specify something called “job definitions”. If you have worked with Amazon ECS, then these are AWS Batch equivalents to ECS Task Definitions. The internal function
pybatch.run_on_awsbatchcreates job definitions on the fly for given arguments. -
Almost all batch jobs we have use S3 as the data store; inputs are pulled from S3 and pushed to some other location in S3. All data is immutable. In some cases outputs are pushed to a PostgreSQL database instead. We’ve had some blog posts related to immutable data before in our blog.
-
The actual amount of data we have is much more than just one day with 8 shard files ;) We also have hundreds of different batch jobs, using a diverse set of technologies.
Batchiepatchie
Once jobs have been submitted, they will eventually run and (hopefully) will do their job, but sometimes batch jobs will fail. Perhaps someone introduced a bug in the code or the EC2 instance running the jobs failed for some reason. Maybe some job became really slow because of quirks in the data.
To investigate and debug issues like this, you need monitoring.
Unfortunately, we feel the AWS Batch console in AWS Management Console leaves a lot to be desired, especially if you really scale up your batch job use.
-
It is difficult to get a holistic view of all jobs in the system. The UI in the management console will not show all jobs neatly in a single view.
-
The management console forgets about jobs after some time.
-
Searching for jobs based on image name or command line arguments is hard. In fact, searching for any particular job at all is hard.
-
Logs for any batch job is in CloudWatch logs; you have to painstakingly navigate around the management console just to see job logs.
If we only had a few jobs per day it would not be that bad. However, AdRoll submits tens of thousands of batch jobs per day through AWS Batch. It was very clear we needed a much better monitoring solution as we started to scale up.
And this is why we created Batchiepatchie. Batchiepatchie is a monitoring tool for AWS Batch.
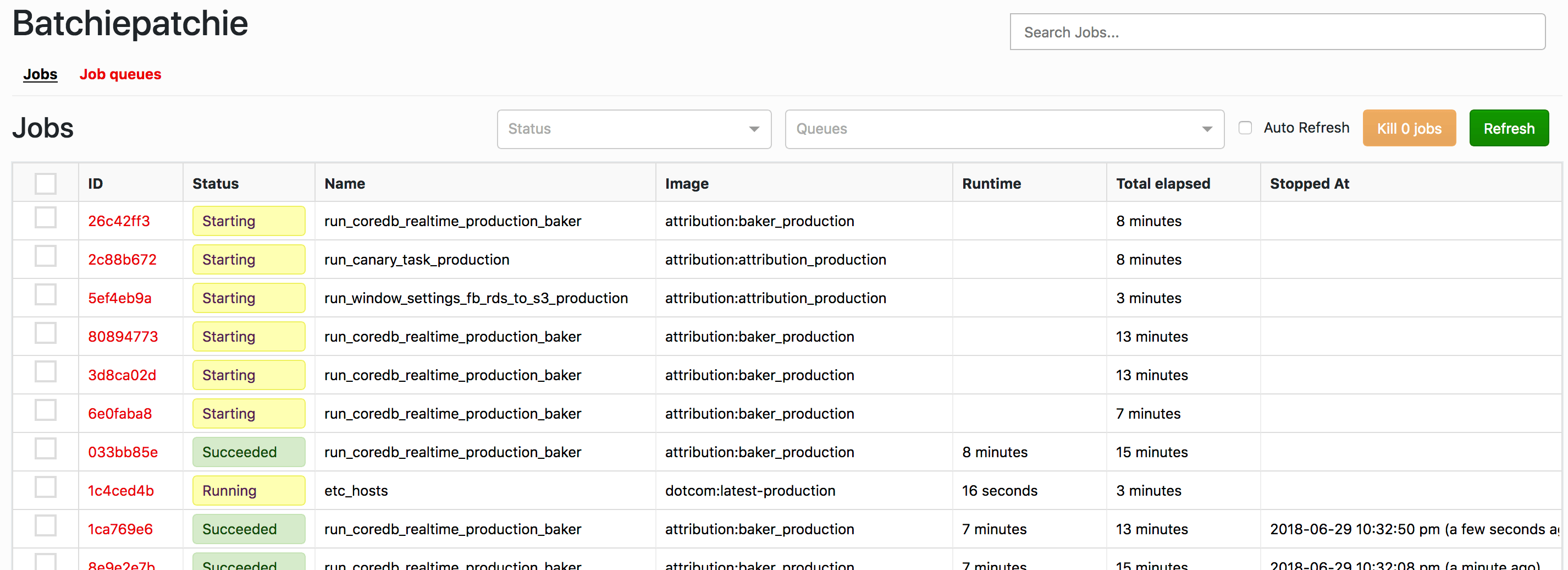
So what does Batchiepatchie do? Pedantically speaking, not much more than AWS Management Console. It just makes certain use cases much faster.
-
Batchiepatchie has a little search box that takes freeform text to find jobs. We spent some time making this feature fast even with millions of jobs in job history. This is by far the most important feature in Batchiepatchie.
-
Batchiepatchie does not forget about jobs. It does not forget about your mistakes either. Ever.
-
Clicking on a job gives you an instant view of its standard output and error.
-
Terminating jobs is easy; select them on the dashboard and kill terminate job.
-
Batchiepatchie figures out IP address of the instances where batch jobs run, making it easier to SSH inside a worker to monitor a job in more detail when necessary.
-
It is easy to link a job page to a coworker.
-
Batchiepatchie implements timeouts for AWS Batch, something that is not supported out of box. This requires some special logic from the code that submits the batch jobs.
When you have tens of thousands of jobs per day, these features can (figuratively) save your life. Finding some specific failed job out of thousands of succeeded jobs is much easier than trying to find it with AWS Batch’s own user interface. Batchiepatchie became so useful at AdRoll that I often see my coworkers refer to AWS Batch as “Batchiepatchie” even though our monitoring tool is just, you know, a monitoring tool.
Batchiepatchie has some more features than listed here; I encourage you to look inside the git repository and read through its documentation if you are interested.
Concluding notes
AdRoll is having a good experience with AWS Batch. Submitting thousands of jobs per day is not a problem in itself; AWS Batch scales up quickly but Amazon’s own monitoring solution is not great, which is why we decided to create a custom monitoring tool designed to be great at finding specific jobs.
As we said, we use Luigi to organize our batch pipeline. AWS Batch does support a simple form of jobs depending on other jobs but we almost always depend on Luigi to handle our dependencies for us instead.
Compared to some other tools like Hadoop or Spark, AWS Batch is Docker-only. This lets you use some pretty exotic technologies inside your batch jobs if you wish to do so. We have Python-written jobs, C and C++ jobs, R jobs, Java jobs and even some Rust and Haskell jobs, sometimes mixed together in one Docker container. You can also select which EC2 instance types you want and get huge boxes to do your computation. If you also use spot instances, you can get these boxes cheap. At AdRoll, we even modified our system images to allow us to memory map more files in a batch job than the Linux kernel allows by default for some truly intensive batch jobs that memory map lots and lots of files.
If you need to build a batch processing pipeline and you like Docker a lot, AWS Batch could be for you. It is a cost effective and a flexible batch job system. We have saved a lot of engineering time by having a reliable batch job system that can be used with a diverse set of technologies. Maybe you can save some of your time as well!
Links
Is your goal in life to build the ultimate batch job pipeline? Roll with Us!