How to save a lot of money with a Baker in the spot market?
OMFG (one-minute file generator) is a service that reads log lines from many Kinesis streams and saves them to S3, creating one compressed file every minute. Its first version was written long ago using Apache Storm, but it became expensive and sometimes unstable over time. Our target was to reduce the service cost significantly and create a 0-downtime infrastructure.
We decided to completely replace the software using Baker, our in-house data processing software (written in Go). We deployed it across all AWS regions by using spot instances only.
The final result exceeded expectations, as we reduced the overall service cost by over 85%.
15 minute read
OMFG, overview and improvement ideas
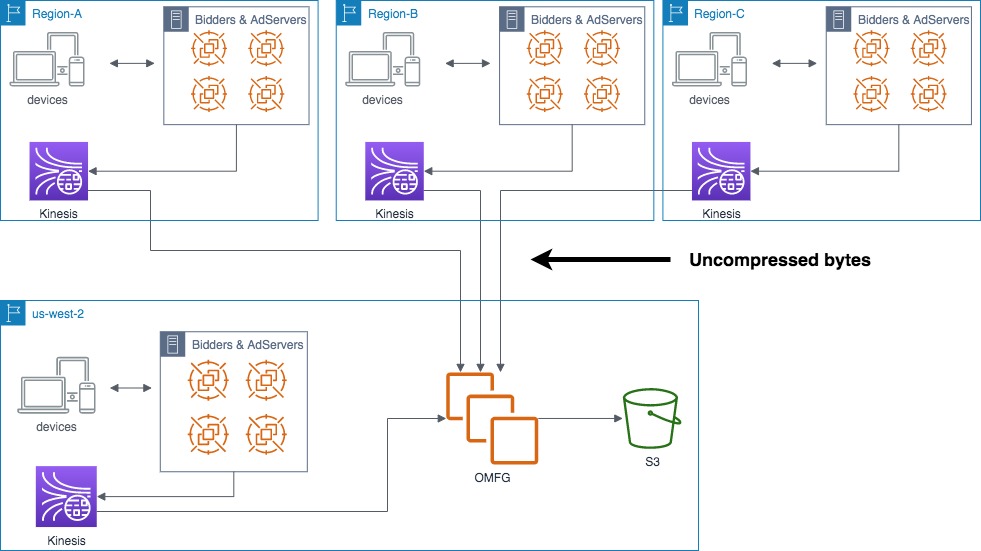
The old OMFG version in the NextRoll infrastructure
Bidders and AdServers produce many terabytes of log lines every day. Those logs are available for consumers through hundreds of kinesis streams spread across 5 AWS regions. Part of those log lines (around 8TB/day) are useful to other services and should be quickly available on S3. Here OMFG enters the scene.
Every minute OMFG takes what has read from Kinesis during the previous minute and compresses it into a single zstandard file per stream, immediately uploaded to S3.
The Storm version used 6 m5ad.4xlarge EC2 reserved instances plus 2 additional c5d.large machines. We thought that using Baker, which is heavily optimized to process log lines, we would have immediately been able to shut down some machines. Moreover, we also decided to move to use EC2 instances from the spot market as previous experiences told us it’s an excellent way to save some money.
A possible alternative to Baker could have been Kinesis Data Firehose, whose job is exactly to “reliably load streaming data into data lakes, data stores and analytics tools”, including S3, our target. Unfortunately, it doesn’t support zstd compression and, moreover, its costs would have been too high: the data streams consumed by OMFG produce more than 1 PetaByte of log lines each month, which means more than $30k/month (not including S3 and data transfer costs). That’s way more than what we ended spending with our custom solution.
Analyzing the service’s detailed costs we realized that only ~25% was spent on the instances, while the data transfer across regions cost around 70%.
That was somewhat surprising and it seemed clear that it should be the first area to focus on to make savings.
Baker, our in-house data processing software
Back in 2016 we decided to try to write a data processor pipeline using Go. The results were so good that the “experiment”, now called Baker, has been highly successful here at NextRoll during the past years and it’s currently used by many teams to process data at PetaByte scale.
Baker works on a “topology”, the description of a pipeline including one input component (where to read the loglines from), zero or more filters, which are functions that can modify loglines (changing fields, dropping them, or even “splitting” them into multiple loglines), and one output component, defining where to send the resulting loglines to (and which columns), also optionally adding a sharding rule. Input/output components support the main AWS services (Kinesis, DyanomDB, S3, SQS) as well as relational databases and in-house products (like the open-sourced TrailDB).
Baker is fully parallel and maximizes the usage of both CPU-bound and I/O bound pipelines. On an AWS c3.4xlarge instance, it can run a simple pipeline (with little processing of log lines) achieving 30k writes per seconds to DynamoDB in 4 regions, using ~1GB of RAM in total, and only a portion of the available CPU (so with room for scaling even further if required).
It is very stable and so optimized for memory and CPU consumption that replacing an existing pipeline with Baker often means greatly reducing the number of servers needed.
This has also been the case for OMFG: with Baker we only use 6 c5.xlarge instances. Compared to the old OMFG version it means 24 vCPUs and 48 GB of RAM instead of 100 vCPUs (-76%) and 392 GB of RAM (-87%).
We are actively working to make Baker an open source software. It will be publicly available over the next months, so stay tuned!
AWS data transfer between regions
AWS datacenter are spread all around the globe
As I mentioned previously, the data transfer to our main region us-west-2 from the other regions represented by far the most significant costs of OMFG.
The original OMFG service was deployed entirely in us-west-2 while the log lines were produced (and thus read by OMFG) in all the 5 regions used by NextRoll. The log lines, produced inside Kinesis, are uncompressed, and transferring all those bytes to us-west-2 was very expensive. In fact, AWS charges for outbound or inter-region bandwidth, while it doesn’t charge for data transfer within the same availability zone or data transfer between some services in the same region (like Kinesis to EC2).
For this reason we decided to create a split infrastructure, deploying OMFG on multiple ECS clusters across the globe (one per region), reading uncompressed data from the Kinesis in the same region (with no costs) and transferring the files to us-west-2 after compression.
Fun fact about EC2 data transfer prices is that, while outbound bandwidth costs decrease when the volume increases, data transfer prices between AWS regions are constant. The latter is generally lower than the former, but it can be unexpectedly higher in some cases. For example, data transfer from EC2 to the internet in Tokyo costs $0.084 per GB when transferring more than 150TB/month, while transferring data to another region costs $0.09 per GB. In Singapore, it’s even more: $0.09 per GB between regions and $0.08 per GB to the internet.
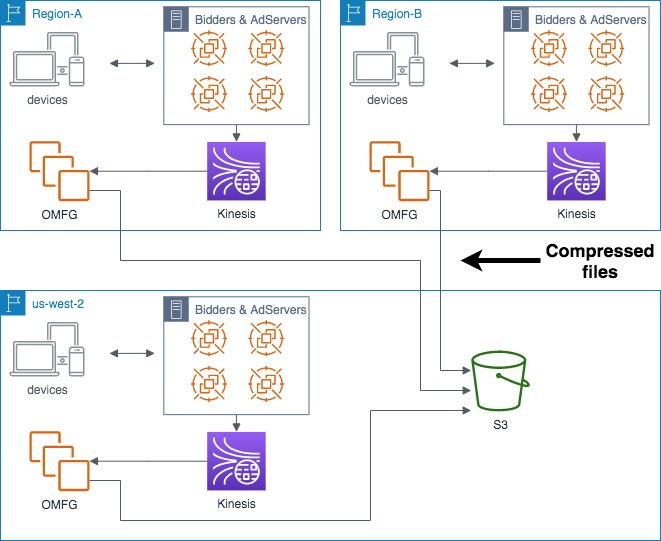
The new OMFG, deployed in multiple regions
The compression ratio was the key to this idea of distributed deployment. An overly low ratio would not have balanced the distributed deployment costs of a centralized solution.
The default zstd compression level (3) is good enough (~9x compression ratio), but after some testing we found out that it’s easy to obtain better results using the long range mode.
In the chart below we can see an example of compression ratios on one of our log line types. Also without the long range mode (red line) it’s possible to increase the default compression ratio using higher values, but the cost in terms of lost speed is not particularly low. Level 10 seemed a good compromise for us because it performs almost like smaller levels but has a good jump in the ratio (>10x).
Maintaining the same compression level (10) but using the long range mode (enabled with the --long option) at level 27 (the default, with a 128MB window size) we see a big jump to >13x ratio (blue line) with a small decrease of speed. Larger window sizes still slightly increase the compression ratio. Still, they have a significant drawback: the default zstd decompression parameters allow for using values of the --long option up to 27 without having to add any new option to the decompressor. Beyond that number, the decompressor must use an equivalent parameter, which would require updating each reader, which was incompatible with our use case.
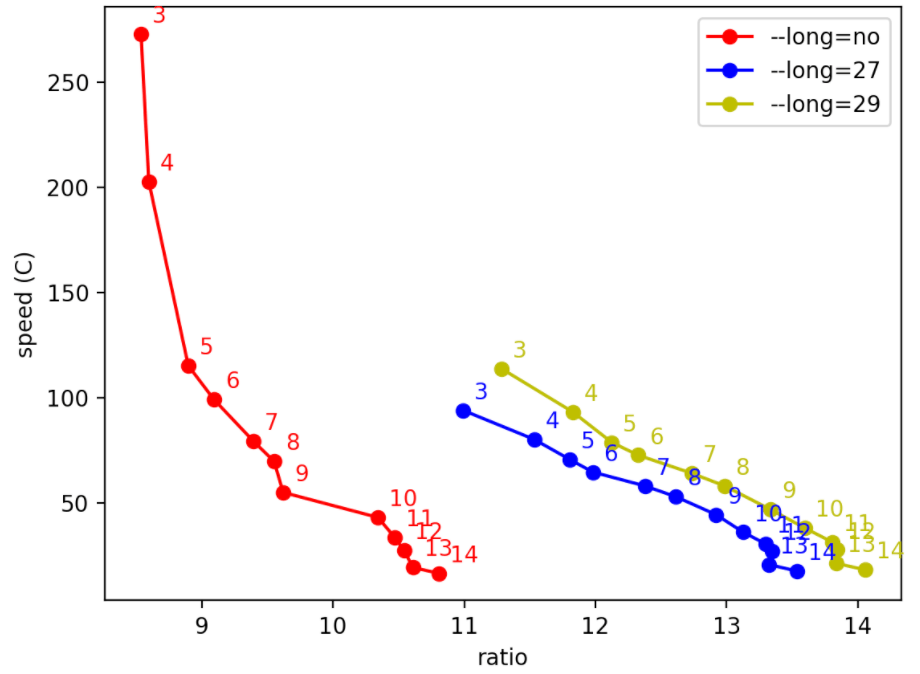
How the zstandard long range mode impacts the compression ratio
So, ultimately, we used the compression level 10 with the default long range mode window size.
The resulting compression ratios range from 4x to 30x on average, with peaks at 100x (performances depend on log lines type and sizes).
ECS and spot market, a not-so-smooth relationship

The new OMFG runs on Elastic Container Service clusters as Docker containers. We decided to use EC2 spot instances to provide computational power because they can ensure significant savings (>65% on the instance types we use). But by its very nature, a spot instance can be stopped by Amazon at any time, and the availability of the chosen instance types can change based on the fluctuation in the market demand.
To address the change in availability we started introducing a long list of possible instance types, decreasing the chance of running out of instances.
But spot interruptions will still happen, and OMFG must provide an almost realtime service, with a maximum delay in uploading the files to S3 of ~5 minutes. In small clusters such as ours (1-2 instances per region), an interruption has a vast impact, stopping 40-100% of the running docker containers. The Auto Scaling Group (ASG) we use to manage the active instances in the cluster requires some time to perceive the interruption and replace the missing machine, with an average downtime of 8 minutes, too high for us.
When AWS decides to stop a spot instance, 120 seconds are conceded before the operating system enters the shutdown phase. During these 2 minutes, it is necessary to perform a graceful shutdown saving all data currently been processed by Baker. Otherwise, it will be lost (there is, in any case, a way to recover data if using non-“volatile” disks, a subject that we wrote about in a past article).
Since an official solution doesn’t exist to address the spot instance eviction, we had to craft our own.
Solution
The solution we have found is to check whether a server eviction is happening and, where necessary, to perform a controlled shutdown of the containers. AWS provides notification of imminent shutdown through the Instance Metadata Service at http://169.254.169.254/latest/meta-data/spot/instance-action, which returns a 200 HTTP code only when the instance is in the interruption phase. That’s the signal that triggers our cleanup.
This excerpt from the script that we use is executed as a daemon by the operating system (we forge our AMIs with Packer). It checks the spot interruption endpoint every 5 seconds and, when the interruption is intercepted, it increases the number of desired instances in the ASG, triggering an immediate launch of a new server. Moreover, it sends a SIGINT signal to the Docker containers, which is captured by Baker to perform a graceful shutdown, stop the Kinesis consumers and upload all the files before quitting (this generally requires less than 1 minute):
#!/bin/bash
REGION=$(curl -s http://169.254.169.254/latest/dynamic/instance-identity/document|grep region|awk -F\" '{print $4}')
ASG="<asg_name>"
while true; do
CODE=$(curl -LI -o /dev/null -w '%{http_code}\n' -s http://169.254.169.254/latest/meta-data/spot/instance-action)
if [ "${CODE}" == "200" ]; then
# ...
# Kill gracefully all OMFG containers
for i in $(docker ps --filter 'name=omfg' -q)
do
docker kill --signal=SIGINT "${i}"
done
# Immediately increase the desired instances in the ASG
CURRENT_DESIRED=$(aws autoscaling describe-auto-scaling-groups --region "${REGION}" --auto-scaling-group-names ${ASG} | \
jq '.AutoScalingGroups | .[0] | .DesiredCapacity')
NEW_DESIRED=$((CURRENT_DESIRED + 1))
aws autoscaling set-desired-capacity --region "${REGION}" --auto-scaling-group-name "${ASG}" --desired-capacity "${NEW_DESIRED}"
# ...
fi
sleep 5
doneTogether with this script, the ECS agent in the instance is configured to set the instance status to DRAINING when it receives a spot interruption notice (automatically done by ECS when ECS_ENABLE_SPOT_INSTANCE_DRAINING=true is set in /etc/ecs/ecs.config, see the official documentation for details).
Setting the instance status as DRAINING results in stopped containers not starting again in that server but, instead, being launched in the new instance when ready.
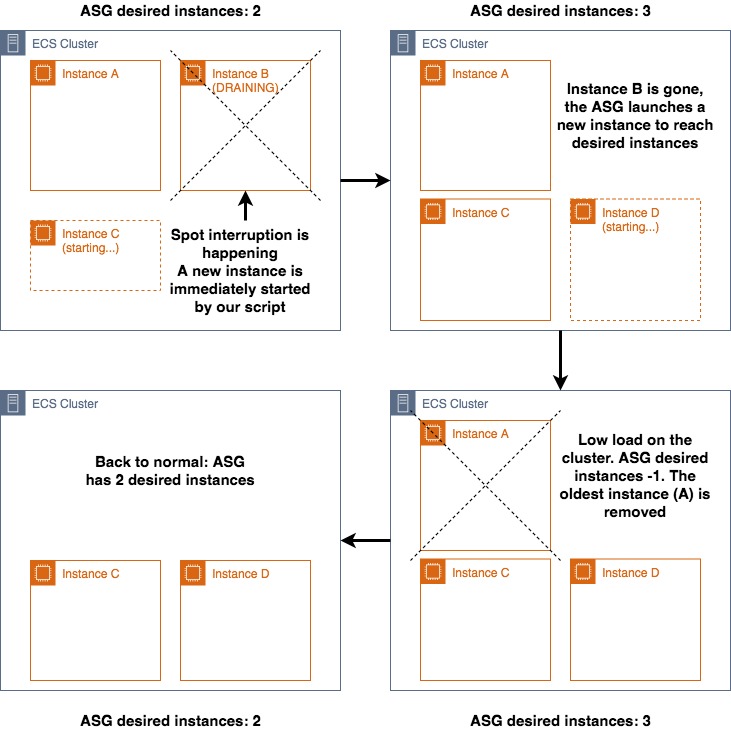
How OMFG manages a spot interruption
This solution permits a final downtime of less than a minute.
There’s only a small downside that is shown in the picture above: adding a desired instance to the ASG during the eviction means that another instance is launched when the interrupted machine is stopped, resulting in an exceeding server compared to the previous desired number of instances.
This additional machine though will only live for a few minutes, until the ASG will shut it down because its usage is too low, bringing the ASG configuration to its default values.
Not perfect but still a good and working solution.
Containers autobalance
ECS lacks one important feature: balancing the docker containers across the available EC2 instances.
When a cluster is freshly launched the containers are created in a balanced manner (same number on each server), but when an instance interruption occurs, the tasks are stopped and started again into the available machines (and this happens in seconds, before the new one starts). Then the new machine will be empty or at most with the tasks remaining from the previous operation (because they couldn’t find sufficient free resources on the existing servers to be launched).
As ECS does not provide tools to balance the tasks in the cluster automatically, we, therefore, need to do it ourselves.
Solution
The solution we have found is to run a scheduled task every 15 minutes checking the number of tasks in each RUNNING instance and balancing them if the difference is excessive.
The job “counts” the number of containers per server and moves them if the cluster is unbalanced (count difference >35%).
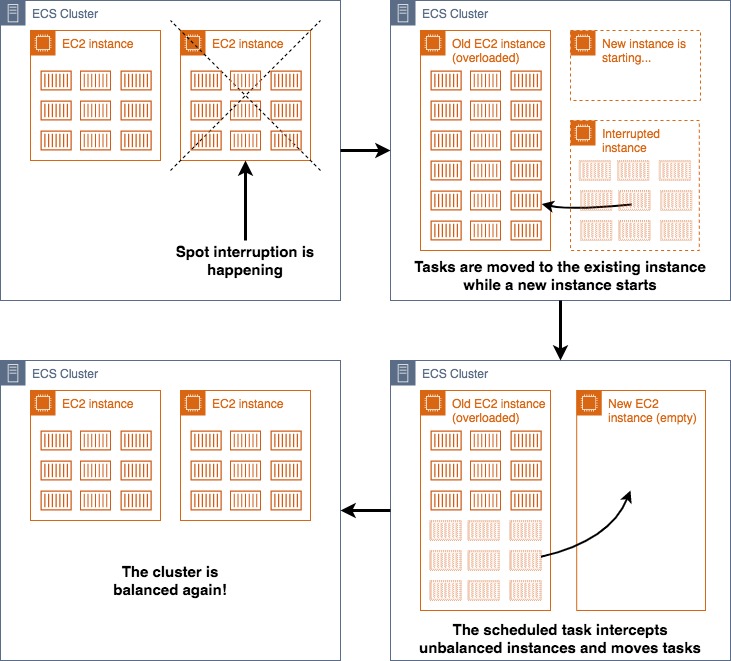
How the autobalancing scheduled task works
Replacing all instances without downtime
Sooner or later it will be necessary to replace the instances of the cluster with new versions, typically because the AMI has been updated.
In itself, the operation is not particularly complicated, essentially only manually turn off the machines and they will be replaced with new units that use the updated version of the AMI.
The problem is that this operation leads to a downtime of the service. That is between the moment in which the instances are turned off and when, after restarting, all the tasks have been automatically launched (more than 8 minutes in our tests). We then found a solution that allows us to launch all the tasks in the new machines before turning off the old ones and, thus, the old instances, taking advantage of the operation of the autoscaling groups.
Solution
The trick is to implement the following steps, which can be performed manually as well as by an automatic script that makes calls to AWS APIs (the latter is our solution):
- Set all instances of the cluster to the
DRAININGstate. Nothing will happen as there are no otherACTIVEinstances on which to move tasks. - Double the number of desired instances in the autoscaling group. These new requests are launched in the
ACTIVEstate and all the tasks are started on them thanks to the previous step. As they are launched, similar tasks are also turned off in theDRAININGunits. Baker, as mentioned above, performs a graceful shutdown saving all its current work. - Wait until all the tasks have been turned off on old instances, which means they are active on new ones.
- Return the ASG number to the previous value. The ASG shuts down the excess machines bringing the situation back to its initial state.
This latter point deserves a broader focus. Turning off excess machines does not in itself guarantee that the machines just launched are not turned off again.
The key is to set the termination policy of the autoscaling group to OldestInstance. We are telling the ASG that, if a unit has to end, the choice must fall on the oldest one, precisely what we want.
Conclusion
What is the final outcome of our work?
- We saved 85% on EC2 costs migrating to Baker (and thus reducing the number and size of instances) and moving to the spot market.
- We also saved 90% on data transfer costs compressing all records in their origin regions before sending them to S3.
- We incurred some minor additional costs on DynamoDB due to how Baker works with Kinesis.
The final saving was 85% compared to the cost of the previous version, a great result.
We have learned a lot from this experience and we are now replaying it on other similar services.