Announcing TrailDB - An Efficient Library for Storing and Processing Event Data
![]()
tl;dr Today, we are open-sourcing TrailDB, a core library powering AdRoll. TrailDB makes it fast and fun to handle event data. Find it at traildb.io.
Problem: Event Data
Imagine that you have a large amount of event data that looks like this:
2016-05-02T22:48:38 user023 view features
2016-05-02T22:49:01 user301 click graph
2016-05-02T23:03:02 user023 view pricing
2016-05-02T23:15:45 user187 submit signup
2016-05-02T23:35:23 user521 view about
2016-05-02T23:58:11 user004 click graph
2016-05-03T00:02:09 user023 submit signup
Data like these could be generated by any web application: each event has a timestamp, a user identifier, a token describing the action, and its target.
One could store the events in a relational database, in a table events with the above four columns. The table makes it easy to query aggregate statistics, like signups by day:
SELECT date_trunc('day', timestamp), count(*)
FROM events
WHERE target='signup'
GROUP BY 1;Aggregate queries like this are the bread and butter of data analytics. There are many excellent, scalable databases such as Amazon Redshift or Presto which can handle such queries this with ease.
User-level Analytics
There is another class of queries that are considerably harder to express in SQL. Notice how in the example data above, user023 first comes to the site, views a page about product features, then views a page about pricing, and finally signs up after about an hour since the first event.
Let’s say you wanted to count the number of users who sign up in less than an hour since the first event. One way of doing this in SQL is to use window functions. Window functions are a powerful feature of SQL but unfortunately they can be quite hard to grasp.
Over the past years at AdRoll, we have seen a growing number of use cases for user-level analytics. The use cases vary from computing metrics like bounce rate to fraud detection and feature extraction for machine learning. Theoretically, all these use cases could be solved with sufficiently advanced SQL queries but it is hardly practical. Alternatively, the queries could be expressed as Hadoop or Spark jobs.
None of these solutions felt sufficiently flexible for all use cases. Relational databases are not well-suited for computationally demanding jobs: none of the existing relational databases can scale automatically and smoothly based on the query load. Frameworks like Hadoop or Spark impose their own constraints on how to express algorithms, and what languages, libraries, and infrastructure can be used.
Solution: TrailDB
TrailDB is a library implemented in C, which is optimized for storing and querying series of events at the user level. Its data model is specifically designed for use cases like those described above:
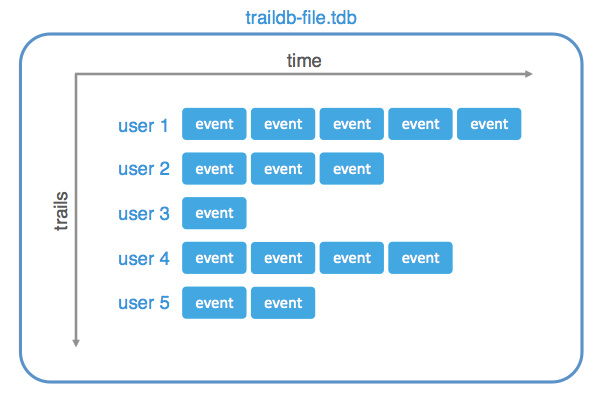
TrailDB’s secret sauce is data compression. It leverages predictability of time-based data to compress your data to a fraction of their original sizes. In contrast to traditional compression, you can query the encoded data directly, decompressing only the parts you need.
TrailDB provides a straightforward API for querying events by user efficiently. The API is thoroughly performance-driven: Not only does it allow you to query events quickly, but it also encourages programming patterns that make the surrounding application fast.
Designed for the Cloud
TrailDBs are immutable files which your application can create and access using the TrailDB library. This is a deliberate design choice: compressed, immutable files like these are a perfect match for modern, distributed, elastic cloud environments. You can store TrailDBs as you see fit; we find that Amazon S3 provides virtually unlimited throughput for your data, and you can process them with an auto-scaling cluster of (spot) instances which provides virtually unlimited computing power.
TrailDB by itself is a simple library, decoupled from infrastructure, which is designed to do one thing well: compress event data and provide high-performance access to them. It integrates seamlessly to elastic data pipelines as described in a previous blog article, Petabyte-Scale Data Pipelines with Docker, Luigi and Elastic Spot Instances.
All together, our elastic stack for processing event data in AWS looks like this:
This stack allows us to perform a massive amount of computation cost-efficiently without any performance bottlenecks. S3 has proven to be able to provide amazing aggregate throughput to hundreds of concurrent instances, so TrailDBs can be accessed quickly.
Thanks to TrailDB’s various language bindings, we can use the best tool for each job. Some computationally intensive jobs are written in C or D. Some jobs rely on external libraries which are convenient to access in Python or R. Naturally not all use cases are batch jobs; we have services written in Go and even Haskell which access TrailDBs.
As TrailDB is a library, not a framework, it allows you to structure your program in the most idiomatic way, which is great for productivity. Docker removes deployment headaches by encapsulating everything in well-behaved containers.
Thanks to Quentin and auto-scaling groups, we can optimize instance types for each workload, some of which are IO-bound while others require more CPU. Finally, Luigi makes a job graph of tens of inter-dependent jobs manageable.
TrailDB at AdRoll
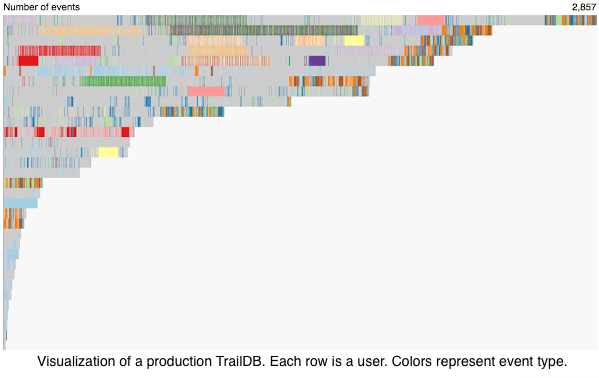
TrailDB has been used in production at AdRoll for about one and a half years. During this time, we have stored tens of trillions of events in TrailDBs. Today, the TrailDBs are queried by almost a thousand jobs daily.
As TrailDB is a core component of our data infrastructure, we take robustness and testing seriously. The unit test coverage of TrailDB is nearly 100%. TrailDB is also hardened by a number of integration tests. As a result of long-term production use, we take backwards compatibility very seriously: not a single time during the history of TrailDB we have broken backwards compatibility so that old TrailDBs could not be read anymore. We intend to keep it this way.
We have a number of tools built on top of TrailDB which make computing various user-level metrics easier. We are planning to open-source some of these tools in the future. Adroll continues active development of TrailDB and we hope that the wider community finds it useful as well.
Learn More
You can find TrailDB with extensive documentation at traildb.io.
The quickest way to get started is to read the installation instructions and walk through the TrailDB tutorial.
If you want to learn more about the background and internals of TrailDB, you can watch a presentation about TrailDB on YouTube and browse the slides of the presentation here.
If you have any questions, you can find us in the TrailDB Gitter channel.