Collider: A New Frontier in Testing
Introduction
Advertising is a competitive market. This probably won’t be the first time you hear something like that, but it’s absolutely true. For every move you make, you have to consider your competitors are getting a step closer to you. Speed and precision are key to the success of the business, but how can we guarantee these with the stress of such a large system? Is that pricing strategy better than what we are running right now? Would we improve the performance of our bids, or just burn money? Handling billions of requests may make changing a simple digit an odyssey that can end extremely badly, costing a significant chunk of revenue.
Considering the need and the risk, there is a single solution: iterating fast, but in a controlled manner. Risking all of our revenue by deploying an idea would get, in the best case scenario, our business intelligence team to raise an eyebrow. So why don’t we risk just a fraction of our traffic? Let’s construct an experiment, specify our study group, and fire away. No complicated deployments, no significant risk of the whole system catching on fire, and immediate feedback on how that experiment is performing.
Regardless of how cumbersome and slow a regular deployment process is, that’s something to worry about at a later time. Now is the time to do some good, old-fashioned trial and error, but in a healthy, controlled manner.
Collider
How can we iterate in that swift, controlled manner while taking less than 10 minutes to deploy a new set of tests? Easy: everything comes back to Erlang.
If you are unfamiliar with Erlang, you are missing out on a magnificent language with myriad smart features. This functional language was developed with a simple idea in mind: being able to process thousands of parallel requests in a concurrent manner. It was a perfect fit for our real-time bidders. These bidders handle hundreds of thousands of requests per second and have to respond on rigid deadlines, so concurrent and lightweight processes are a must. We’ll focus on a couple smart features: isolation and “hot swap.”
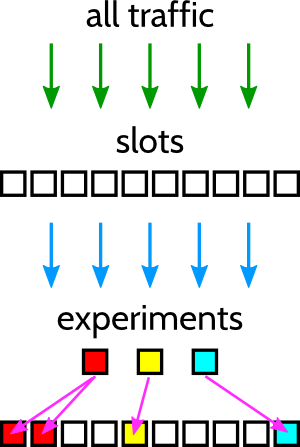
Our experiment framework is called Collider. As we mentioned, we want to be able to run these experiments in as much isolation as possible. This framework splits the total traffic received by a single box into a set of slots. Do we think that an experiment would need a big sample for proving its efficacy? We assign a big percentage of our traffic to that experiment, but we rest assured that the untouched slots are completely safe and unaffected by any crazy ideas. Erlang guarantees isolation on each process, so even if we deploy a wild piece of code, the system will ensure only that fraction of traffic is affected. Also, as we are controlling strict deadlines internally (as we have timeout requirements for third parties), even if we try to connect to external components, the requests will be expired and cleaned before they can affect the rest of the system.
And what about that “hot swap” thing? Erlang allows us to hot reload code without any complicated ritual. We simply replace the previous version of our code on the filesystem and, poof!, the code will seamlessly be replaced for the whole runtime. It’s as easy as that. Instead of thinking about bringing down boxes and waiting for a new version to propagate, we simply pack our Collider experiment bundle and fire it off to S3. In no time at all, the boxes will be running the new set of tests and expiring those that are no longer needed. Zero impact, zero downtime, immediate success.
Integrations
“Okay, that sounds interesting, but what’s an ‘experiment?’ What can this Collider thing test?” This is one of the best aspects of Collider, as the infrastructure is prepared for handling all types of experiments.
You may have heard about real-time bidding that it’s not only about being fast, it’s also about being smart about where to spend money. “How probable is it that this person will click on this ad? Do we need to go all out or will our money be wasted on this potential impression?” Having to reply to these kinds of questions without the appropriate data is a gamble, and that’s why the bidders rely on our BidIQ machine learning system.
BidIQ trains on the data we have seen so far, extracting information from select features of our traffic. It then uses these features to return a performance prediction and bid price. But when we want to add new training features to that system, it’s not always easy to see which new criteria may be good indicators about the quality of a bid request. For these scenarios, Collider is a perfect fit, allowing us to do an A/B test in a controlled manner with live traffic. Once the data science peeps are happy with the results, that new model can be moved into production, becoming the default model that predicts prices for all of our traffic.
But our integrations don’t end here. For example, when several ads are available to display to the same user, what criteria should we use to decide which ad is best? Or, is this real traffic or fraud? All these variables take place in different parts of our real-time bid flow, but the Collider framework is sufficiently generalized to inject itself into all of these places. We can change the behavior of key parts of our system in a transparent way, and for a small percentage of traffic in a completely isolated way. In order to keep our fingers on the system’s pulse, all results can be monitored on different dashboards with our analytics tools.
Even better, when defining the slots for splitting our traffic, they can be reused, allowing us to combine different experimental behaviors across the system. Essentially, we can control whether we’re testing independent or correlated variables. For example, say we have a new, more aggressive BidIQ version and we want to combine it with a new internal auction strategy to select from all available ads. Reusing the same slots on both experiments would achieve the desired effect. In the image below, we can see how distributing slots appropriately will not affect our tests. The comparison of red, green, and white in the top layer is fine because each of those is subjected to proportionally the same amount of blue traffic. Similarly, on the second layer, the blue traffic is subjected to the same amount of red, green, and white traffic from the top layer as the white traffic in its layer.

Can it get any better?
Even with a swift deployment process, flexibility, and monitoring, we still have plenty of exciting features to implement on Collider and its environment.
Right now, testing locally can take a while, especially when tests get more complicated or require specific external components available on production. Most of the time would be spent setting everything up to replicate production in an accurate manner (and with high odds of something missing). One of our short-term goals is automatically creating staging environments to push a release of Collider and let it run with synthetic traffic. In this replica of a production environment, the new version would run for a time until a set of health indicators are achieved. The release would then be ready to be shot into production (with human intervention, of course), across the board.
This may look like a contradiction with a tight development cycle, but it allows for less tech-savvy parts of the company to create tests without requiring engineering time to debug them. For that reason, we would like to provide new, simple interfaces to set parameters on tests so anyone with the right permissions can fiddle with them.
If working in such a fast-paced environment sounds enticing and you are in love with new and exciting technologies for high traffic volumes, don’t think twice: drop us a line!