Chasing a Performance Regression with Erlang/OTP 22
Updating the underlying systems that our service depends on (be them operating system, VMs, core libraries, databases, or other components) is a regular part of our systems’ lifecycle. In this post, we’ll discuss how we found a performance regression when updating to a newer erlang OTP release, the steps we took to investigate it, and how we worked around the specific issue at hand.
OTP Update Cadence
For a big part of our core tech running on Erlang, years ago we settled on a policy to run on the second to last OTP release. The reasoning behind this was to avoid being subject to bugs or performance issues that might still exist on the freshest release. The idea was also to wait a bit till new features settle down before rushing to adopt them. It is not written in stone, but it is a rule we try to respect.
Following this workflow, we first tried to migrate from OTP21 to OTP22 some months ago, as OTP23 was released. But much to our dismay, this wasn’t as smooth as we would have liked.
Performance Drop
As part of our release process, we ran the new release parallel with the previous one and looked for any anomaly or performance degradation that could impact us. In this case, it was immediately noticeable that we were hitting some problems when running on OTP22, as the service’s production throughput was lower. Noticeably lower: our system was running at ~0.75x of what it was before.
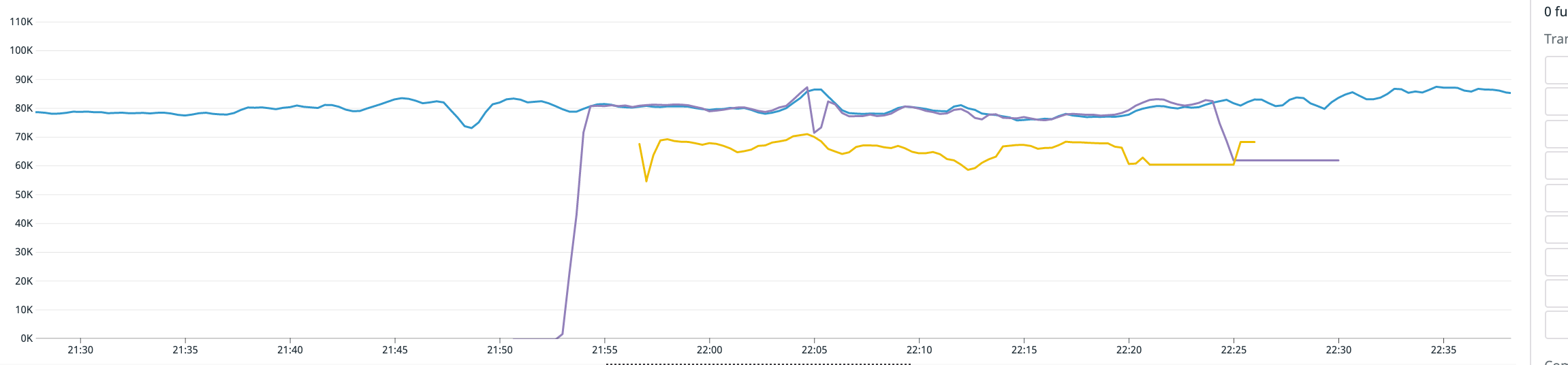
Throughput when switching to OTP22 (yellow) vs. throughput on our production system running OTP21 (blue) and a control group (purple)
The first thing we tried was to look at the release notes. Was there any change that could have this kind of unexpected impact on our system? We were looking for things we thought could have this kind of significant impact, like…
- Changes to BEAM startup parameters and default values
- Changes to socket/networking implementation
- Changes related to literal terms (we have tons of data that is preprocessed and backed in
persistent_termat startup time)
Initially, nothing stood out as suspicious.
The Plot Thickens
Then we looked at what the system was actually doing, and it was evident that it was spending much more time on system-cpu than before:
[ec2-user@ip-172-26-77-44 ~]$ mpstat -P ALL 5
Linux 4.14.177-107.254.amzn1.x86_64 (ip-172-26-77-44) 06/08/2020 _x86_64_ (16 CPU)
07:44:51 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
07:44:56 PM all 62.28 0.00 16.24 0.00 0.00 0.61 0.41 0.00 20.46
07:44:56 PM 0 21.22 0.00 4.69 0.00 0.00 0.00 0.61 0.00 73.47
07:44:56 PM 1 62.37 0.00 17.71 0.00 0.00 4.63 0.40 0.00 14.89
07:44:56 PM 2 65.09 0.00 17.25 0.00 0.00 0.00 0.41 0.00 17.25
07:44:56 PM 3 65.58 0.00 16.50 0.00 0.00 0.00 0.41 0.00 17.52
07:44:56 PM 4 66.94 0.00 15.70 0.00 0.00 0.00 0.41 0.00 16.94
07:44:56 PM 5 66.67 0.00 16.36 0.00 0.00 0.00 0.41 0.00 16.56
07:44:56 PM 6 65.79 0.00 16.70 0.00 0.00 0.00 0.40 0.00 17.10
07:44:56 PM 7 68.78 0.00 14.69 0.00 0.00 0.00 0.20 0.00 16.33
07:44:56 PM 8 64.62 0.00 15.95 0.00 0.00 0.00 0.61 0.00 18.81
07:44:56 PM 9 67.69 0.00 14.93 0.00 0.00 0.00 0.41 0.00 16.97
07:44:56 PM 10 53.54 0.00 24.65 0.00 0.00 4.85 0.40 0.00 16.57
07:44:56 PM 11 61.89 0.00 19.47 0.00 0.00 0.00 0.41 0.00 18.24
07:44:56 PM 12 62.68 0.00 19.38 0.00 0.00 0.00 0.62 0.00 17.32
07:44:56 PM 13 64.21 0.00 17.79 0.00 0.00 0.00 0.61 0.00 17.38
07:44:56 PM 14 74.49 0.00 10.93 0.00 0.00 0.00 0.40 0.00 14.17
07:44:56 PM 15 64.24 0.00 17.67 0.00 0.00 0.00 0.42 0.00 17.67It’s clear from the %sys column that more than 15% of the CPU time is in kernel tasks across all cores (core 0 is irrelevant to our discussion here since our erlang system doesn’t use it; it’s reserved for other short-lived time-sensitive tasks). The system also had a high % of idle time, so it was clear that it was waiting for something.
Since kernel tasks where up, we compared vmstat output between the two systems. The number of interrupts and context switches was almost double on OTP22…
[ec2-user@ip-172-26-77-44 ~]$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
24 0 0 24724364 63472 1242540 0 0 12 57 1466 981 59 9 31 0 1
19 0 0 24773600 63480 1244352 0 0 0 98 271077 62547 74 12 13 0 0
15 0 0 24930996 63488 1246924 0 0 0 359 248553 61832 74 12 13 0 0
15 0 0 24840760 63496 1247752 0 0 0 1405 250937 48011 74 12 13 0 0
13 0 0 24858236 63504 1249876 0 0 0 664 247081 48183 75 12 12 0 0
17 0 0 24855240 63512 1251484 0 0 0 35 252037 47864 76 12 12 0 0
19 0 0 24911248 63520 1253176 0 0 0 18 243274 48386 75 12 13 0 0
14 0 0 24803668 63528 1253780 0 0 0 22 236502 47642 76 11 12 0 0…than on OTP21:
[ec2-user@ip-172-26-77-50 ~]$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
16 0 0 22068060 63404 1410956 0 0 9 54 1218 513 70 8 21 0 2
17 0 0 22078024 63412 1413436 0 0 0 674 124876 27720 84 7 9 0 0
15 0 0 22120716 63412 1414376 0 0 0 267 119251 26972 84 7 10 0 0
6 0 0 22107168 63420 1415960 0 0 0 602 117711 25838 85 7 8 0 0
17 0 0 22124960 63428 1418760 0 0 0 1528 121784 26970 83 7 10 0 0
12 0 0 22149468 63436 1420380 0 0 0 18 124217 30018 82 7 11 0 0
15 0 0 22135184 63444 1422208 0 0 0 115 121552 27490 86 7 6 0 0Next, we looked at network activity: could it be that the pattern of socket writes/read was different? Even if the data sent and received was the same, were we using more IP packets than before? Were those interrupts network interrupts? The answer to all of those was “NO”. The problem was not on the IO side.
Instead, as System Activity Report told us, we had a huge number of page faults:
$ sudo sar -B 10 10
Linux 4.14.177-107.254.amzn1.x86_64 (ip-172-26-68-64) 08/03/2020 _x86_64_ (16 CPU)
09:21:55 PM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
09:22:05 PM 0.00 243.64 140891.62 0.00 128650.61 0.00 0.00 0.00 0.00
09:22:15 PM 0.00 103.24 135143.62 0.00 129283.20 0.00 0.00 0.00 0.00Note that these were minor page faults. We weren’t thrashing on disk, and we weren’t short on memory.
With this new info, we went back to look at changelogs and release notes, this time, knowing a bit more about what we were looking for. We were looking for any change in allocator settings/workings that could lead to what we were seeing. The “Memory optimization” section at the very bottom of this article caught our attention, and we thought we had a winner. It seemed like a strong possibility that a change having to do with freeing memory could be related to our increasing page faults.
At this point, we rushed and made a quick and dirty patch disabling that new behavior (or that’s what we thought). We retried the test to confirm this was the cause before digging deeper into how to solve it in a more civilized way. Adding to our frustration, this didn’t make a dent in the performance drop, so we decided this particular patch probably wasn’t our issue and continued digging elsewhere.
Git Bisect
While investigating this early on, one problem we had was that we have good, fast ways to generate new releases of our systems based on a given (fixed) OTP release. But generating releases using different OTP versions was a painful and tedious process. This is simply something that our dev infra hadn’t been optimized for. We had to change several configuration and packing files, as well as redeploy our CI pipelines.
This hadn’t been a problem so far as switching OTP releases is usually a once-in-a-year thing, but now it was slowing us down as we wanted to try different OTP versions (we tried other minor releases of the OTP22 family, for instance) as well as BEAM patches. So we went on and solved this issue, making it possible for us to build and test deploy releases with different underlying OTP versions easily and fast, even in parallel.
Armed with this new tool, we went with the brute-force approach: git-bisect the changes between OTP21 and OTP23, until we found the commit where our problem was introduced. The investigation was surprisingly fast to do, and after one afternoon, we saw what looked like the smoking gun. Surprisingly it brought us back to OTP’s PR #2046. It was a bit confusing; hadn’t we ruled that out already?
Looking at the kind of memory-related syscalls we were doing on the newer BEAM, we saw:
$ sudo strace -f -e trace=memory -c -p $pid
% time seconds usecs/call calls errors sys-call
------ ----------- ----------- --------- --------- ----------------
86.91 0.622994 74 8371 madvise
7.39 0.053005 71 746 munmap
5.70 0.040851 62 656 mmapComparing that with the same tracing on OTP21, the difference was that there were no madvise calls on OTP21, while the number of memory allocations was about the same.
Where were we calling madvise?. We used perf to find that out.
$ sudo perf record -e syscalls:sys_enter_madvise -a -g -- sleep 10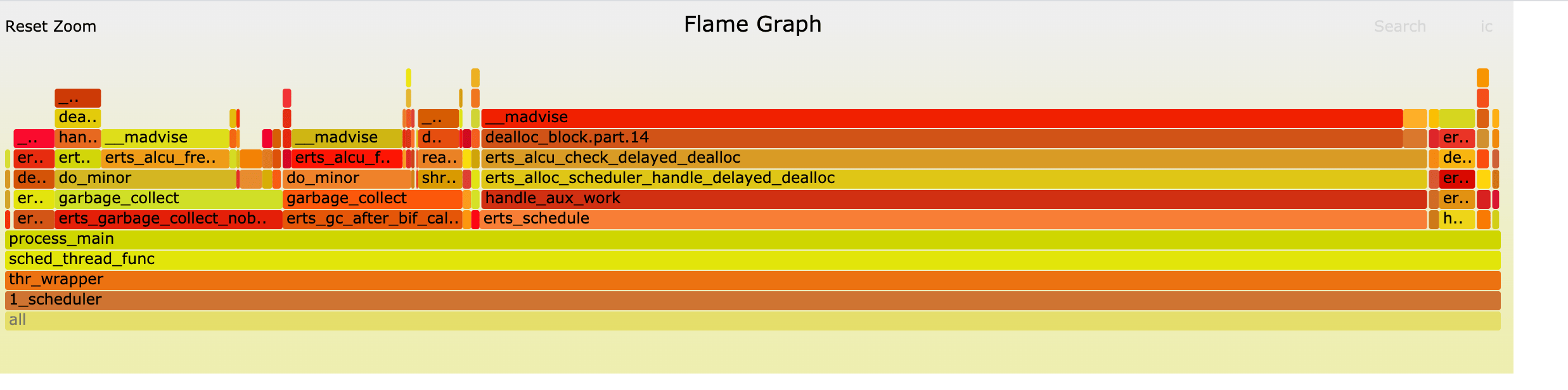
Snapshot of madvise calls, zooming in just one scheduler.
The madvise Patch
At this point, we were pretty sure #2046 was related to our problem, and so we did what we should have done the first time we suspected it: We tried to understand what the patch was doing and what madvise actually means.
The description on the pull request states its intention pretty clearly:
This PR lets the OS reclaim the physical memory associated with free blocks in pooled carriers, reducing the impact of long-lived awkward allocations. A small allocated block will still keep a huge carrier alive, but the carrier’s unused parts will now be available to the OS.
We won’t explain here how the memory allocation is structured on the BEAM. For that, refer to the alloc framework docs and carrier migration docs. There you’ll find an in-depth explanation of pooled carriers.
madvise, the way it’s used here, is a hint to the OS about the usage of a given block of memory. In particular, the BEAM (since OTP22) calls that function to tell the OS that some memory blocks are likely not going to be needed in the near future.
Now that we understood what we were looking at, our performance measurements made sense. Our system was returning carriers to the pool too often and then picking them again shortly after. When returning the carriers to the pool, the new behavior on OTP22 was supposedly hinting to the OS that the free memory there was not expected to be needed again soon.
The question is, why did madvise (MADV_FREE) usage lead to page faults? It is supposed to be a hint to the OS, so it should choose to unmap that memory over others in case of memory pressure. But we never were under memory pressure. As usual, Lukas was very helpful, suggesting that we check if MADV_FREE was actually available on our system. We run on AWS, and we were still using an older version of Amazon Linux which doesn’t support MADV_FREE. So the BEAM falls back to using MADV_DONTNEED, and in that case, the OS was very eager to unmap these memory blocks from our processes, even when memory wasn’t needed elsewhere.
If you want to check if your environment supports MADV_FREE, you can grep for it on .h headers provided by your OS. Or in a perhaps more civilized way, you can compile and run a test program like:
#include <sys/mman.h>
#include <stdio.h>
int main() {
#ifdef MADV_FREE
printf("Congrats, MADV_FREE flag is available\n");
#else
printf(":(\n");
#endif
return 0;
}
Note: the newer Amazon Linux 2 does support MADV_FREE.
How we solved it
Why do we have such a repeated pattern of leaving and picking carriers constantly? This is an interesting question, and it is, in fact, the root of the problem. It means our allocation setting wasn’t appropriate. The settings had not changed in years, while the system had evolved and grown quite a bit during that time. This misusage of carrier pools was present when running on OTP21 as well, of course. It’s just that it was less taxed there.
The solution was to go and improve them, a thing much easier said than done :) (if in doubt, a good starting point is to use erts_alloc_config to get an initial config and iterate from there).
We did several iterations adjusting our settings and improved our memory handling and performance quite a bit, but couldn’t completely eliminate the overhead as carriers were still abandoned too often. This is something we need to investigate further. Carriers aren’t supposed to be pushed in and out of the pool at such a pace. As a temporary workaround that would let us update to OTP22, we disabled carrier migration entirely (this is done by setting the +M<S>acul system flag to 0, replacing <S> with the desired allocators you want to tweak).
A note about the process
As mentioned earlier, we did consider the madvise change as a possible cause of our issue when we started to investigate it. So why did we rule it out when we were initially suspicious about it?
As it turns out, that quick-and-dirty little patch to disable it discussed above was wrong, and it didn’t really disable the thing. This was a regrettable incident and revealed two errors on our side, both caused by rushing to advance on the investigation without taking time to ask why things where the way they were:
- We rushed to do a quick patch to test the hypothesis without fully understanding the code at hand. We disabled one code path calling
madvisebut missed another. - When the hypothesis failed, we again rushed to move on with another work. We didn’t take the time to analyze why our theory was wrong. We didn’t question the experiment’s validity, which would have led us to realize our patch was wrong early on.
There is a broader lesson here: When investigating any complex problem, it’s easy to get overwhelmed by the number of moving parts to consider, but it is crucial not to rush to premature conclusions. You should take your time to understand the problem at hand and how each step moves you a bit closer to the resolution. Knowing what is not the cause of the problem is good progress!