How NextRoll leverages AWS Batch for daily business operations
Describing how NextRoll is handling processing petabytes of data using AWS Batch.
15 minute read
In this blogpost, we are going to review how NextRoll is using AWS Batch for processing data, and how we benefit from this platform. We will start with an overview of the company and explain our needs for data pipelines. Then we’ll talk about how we are utilizing Batch, reviewing the advantages and disadvantages of this technology. Finally, we will show you Batchiepatchie, the product that we have introduced to overcome the challenges presented by Batch.
About NextRoll
NextRoll is an active company in Digital Marketing and Advertisement. Currently, we are serving more than 37,000 brands. These brands from all over the world have trusted us to run marketing campaigns for them.
Our IntentMap features 1.2 billion shopper profiles and trillions of intent data points. Let me emphasize: It’s 1.2 billion profiles for different shoppers across the web. The number of profiles is growing every day.
To keep up with the demand, our machine learning engine is doing 80,000,000,000 predictions every single day. Most machine learning systems would not do billions of predictions in their lifetime, but our system needs to scale up quickly to keep up with the demands, and that number above is not for busy days like Christmas or thanksgiving.
To serve our customers, we are connected to 500 different supply sources across the internet. The sources provide a range of ways to reach customers through banner ads, social media, email, and onsite personalization.
We have three different business units. Each business unit is targetting a different type of customers and fulfilling different needs.
Why Batch?
Given the numbers provided above, we can see that the data that is being generated by digital advertisement is a lot more than anyone can fit in their laptop. Unless you have a massive laptop with terabytes of disk space. That is the first reason that pushed us to look for cloud solutions to orchestrate our tasks.
Over 2019 alone, Batch and Spot market usage has saved us $4,000,000. That saving comes from comparing our model to the usage of EC2 on-demand instances to run our jobs. The saving would be even bigger if you consider the other alternative that is having the servers on-premise. Saving would be less if you compare Batch with EMR or other big data processing that also uses Spot markets, however, the cost would be still less.
Besides cost saving, we have other reasons to use Batch. The freedom of stack is one of them. As long as you can package your requirements into a Dockerfile, and build that docker image, you can deploy it to Batch. This enables us to use a wide variety of technologies in our stack. We have jobs that are written using C/C++, Python, Rust, GoLang, Haskell, Java and other programming languages.
Freedom in the way that data is being processed is another reason. To process this amount of data, we have introduced some file formats, one of them is opensource: TrailDB. These file formats do need special handling for creation and processing that we can handle using Batch. For comparison, Hadoop or Spark do enforce certain types and inputs.
The last item is deployment. The packaged code lives in a docker image, and deployment is as easy as pulling the image from Elastic Container Registry. Besides, since the image is being pulled from ECR to Batch nodes, the whole process ends up being pretty fast.
In a nutshell, these are our reasons to use Batch:
- Cost Saving
- Scale of data
- Freedom of stack
- Custom data processing formats
- Ease of deployment
Growth of Batch usage
Since batch was introduced in 2017, we have been rapidly adapting and using it for more and more reasons. In the table below, you can see a comparison of Batch usage between 2017 and 2019:
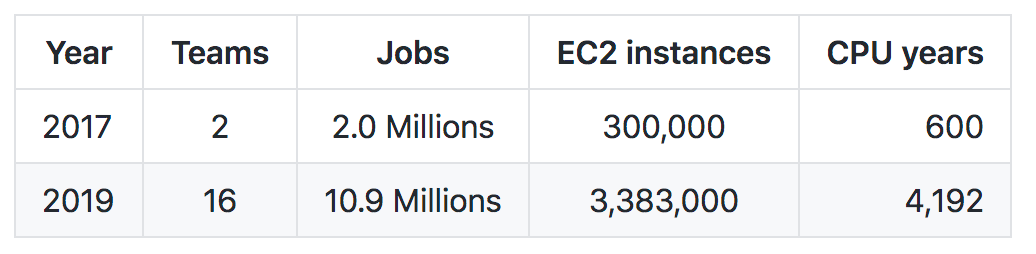
This shows how we grew about 10 times on each metric in only two years. How did this happen? First, we need to account for the growth of NextRoll during this time, but also those stats reveal a clear trend in the adoption of this technology across the company. Especially since teams are autonomous and they are free to use any tech they prefer to accomplish their goals, using Batch points how promising the results were. Additionally, it tells how batch can scale to our needs when we need to.
In the chart below, you can see the number of jobs launched on different dates. 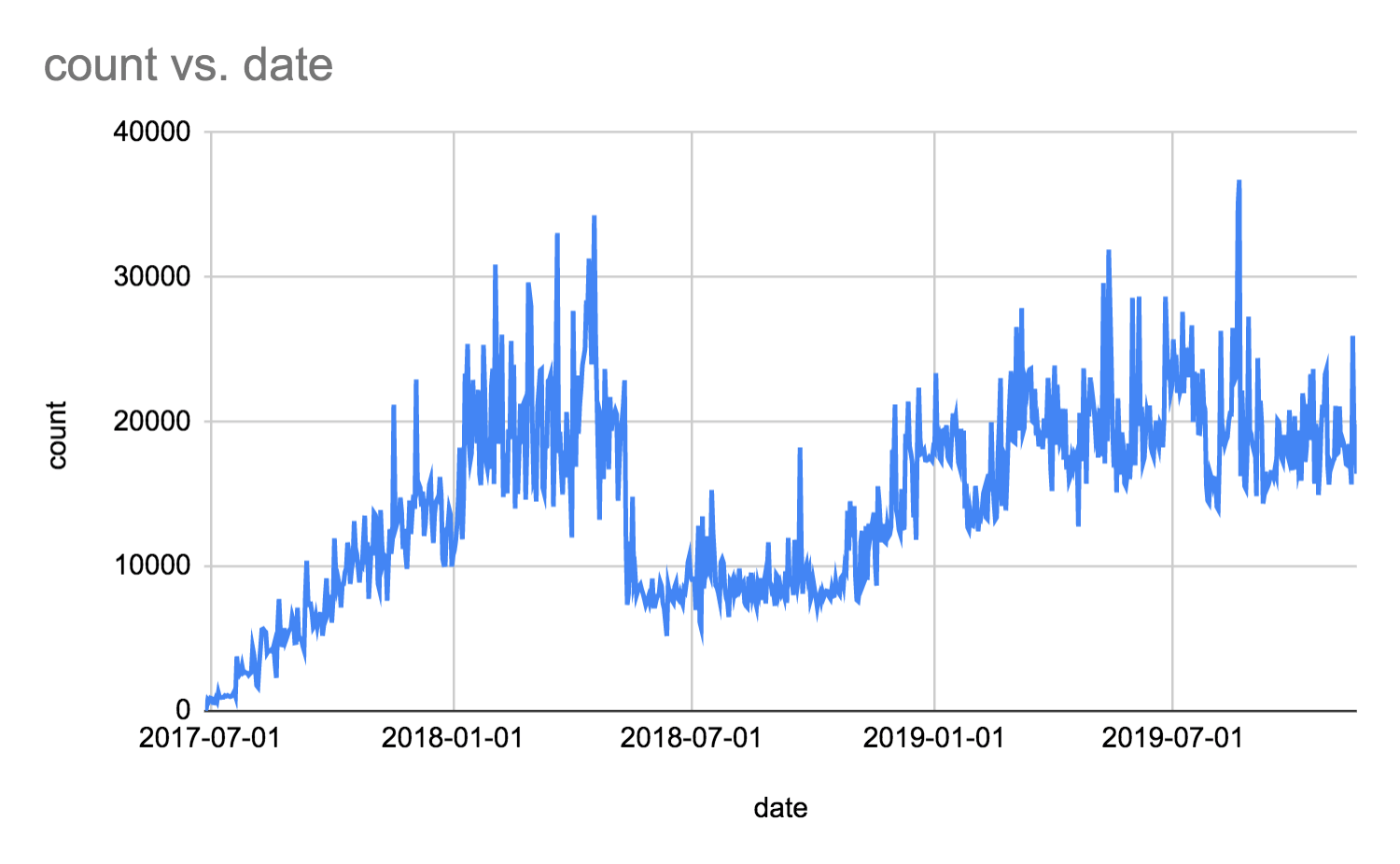
We are constantly improving our pipelines, removing the jobs that are not needed with recent refactors or improving the job run times, and that is why you sometimes see a decrease in the number of jobs. But generally, the trend is upward.
How are we using Batch?
We did publish a blog post regarding how we are submitting jobs to the AWS Batch environment before. In this section, however, we are going to have a more general view, and discuss the challenges on Batch as well.
Data Diagram
The data flow for Batch starts with Jenkins. After checking out the source code and building the Dockerfile, Jenkins builds the docker image and pushes it to ECR. ECR keeps all of the images that we need to run on Batch.
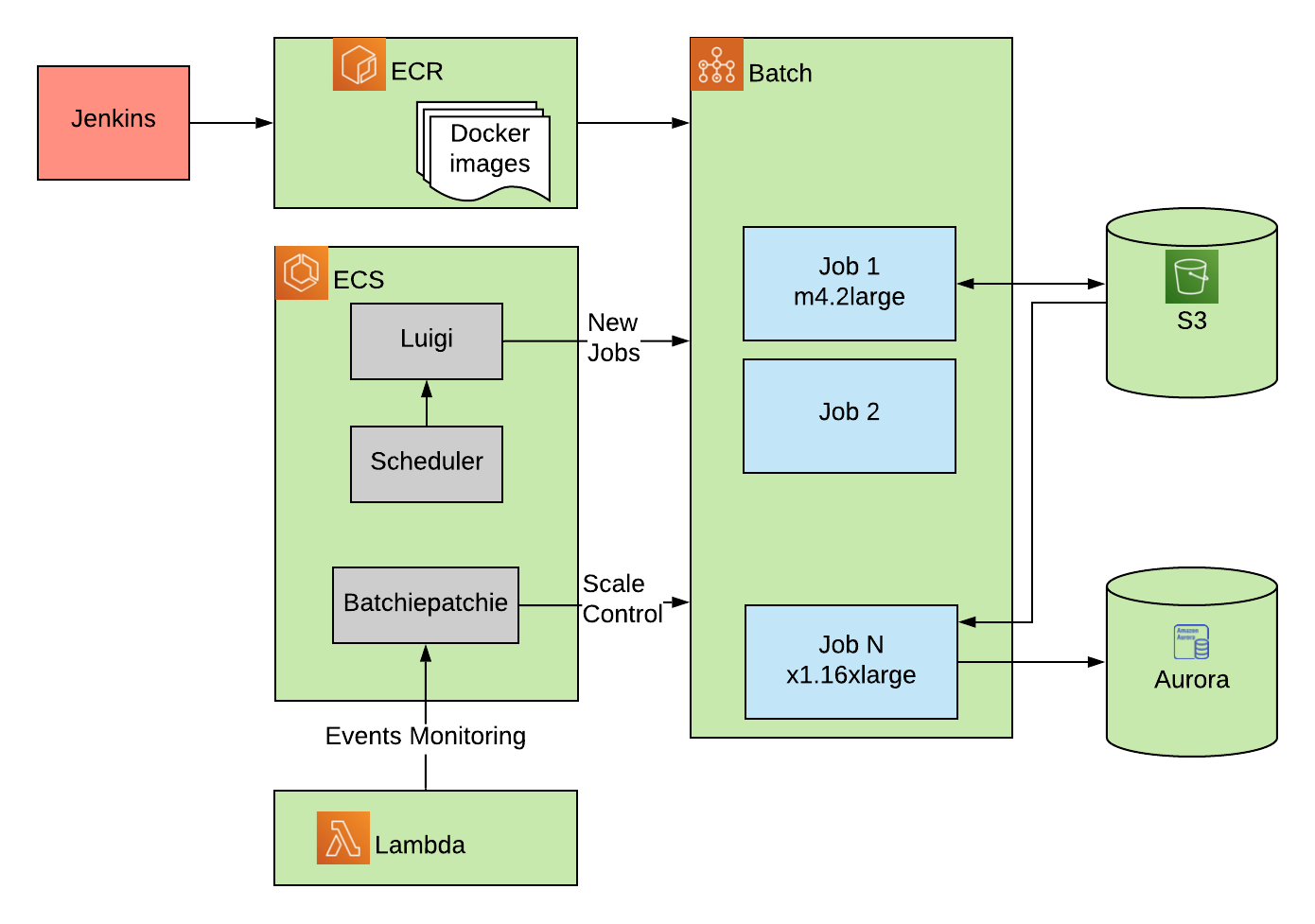
We have some containers running on ECR which control and organize our jobs on ECR. The first one is the scheduler, which kicks off the jobs based on the time of day. Luigi acts as a dependency checker and ensures the dependency of the jobs was met. It also checks if the job was run before. If it did not run before, and all the dependencies are there, the job would be submitted to Batch. We also have our software running on Batch to monitor the jobs, called BatchiePatchie. More about BatchiePatchie, below.
When the job kicks off on Batch, the batch environment provisions an instance pulls the docker image from ECR and runs the command line in the job on it.
Sample job on Batch
Now that we have seen how we submit jobs on Batch, let’s see how one of our sample jobs works on Batch. One of the use cases for us is to convert data from CSV format to TrailDB. The job that we use for this purpose is called Baker. Baker converts data from one form to another and applies some filtering logic to it. It’s like a list comprehension but on a large scale.
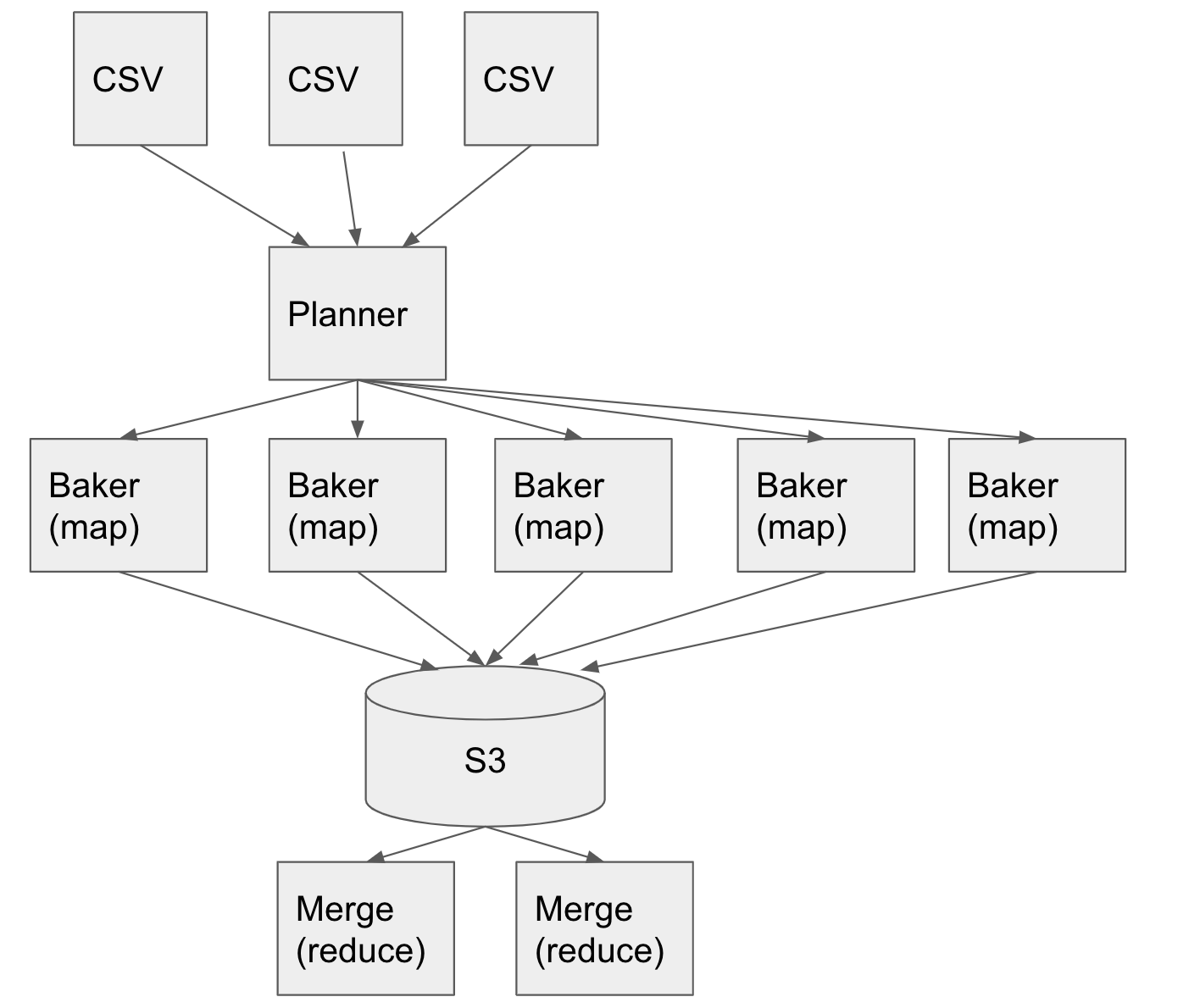
In this example, we have a bunch of CSV files that need to be converted. First, the planner job runs on a specific time of day. The planner reviews the CSV files and the contents. Based on the amount of data and split size, it turns them into several splits. The number of splits would be different on different days and hours. For each split, a baker job is launched on Batch. The Baker jobs perform their conversion and save their output on S3.
Next, the merge jobs run. These act as reduce functions and reduce data to a specific number of shards that are processed later on.
In this example, you see that the data determines the scale of processing. If, for instance, we have only one CSV, one baker and one merger are enough. However, given the amount of our data, we have hundreds of Bakers running every day, and this map-reduce job is running on AWS Batch reliably in our pipeline all the time.
Purpose of the jobs
Going back to what has been mentioned before, we have at least 80B predictions every day, which cause 80B events. Each event is about 1KB, so the prediction events alone are 80TB of information. Jobs that are processing this much data are good candidates to run on Batch.
Attribution
Every day, we are registering about 500,000 conversions. In marketing, a conversion is an event that the customer cares about the most, which mostly is Sales. So you can read it as 500,000 sales. Anyways, for each conversion event, we need to look back 30 days to find out the event that caused that conversion. That requires us to process 30 times 80B which would be more than a few petabytes of information. And this is critically needed to provide reports to our customers.
Machine Learning
We mentioned that our AI system needs to make tens of billions of predictions every day. The model that powers the predictions needs to be refreshed with fresh data periodically. The training for that model also happens on Batch. Batch, in my opinion, is a great tool for training machine learning models. In our case, we have a single case of batch processing that happens once and then is used several times. So models can be trained on Batch and served on a tiny web server.
Generally speaking, Batch is a good use case for:
- Periodic or nightly pipelines
- Automatic scaling processes
- Tasks that are flexible in the stack
- Tasks that can benefit from the use of different instance types
- Orchestrating instances to run tasks
On the topic of instance types, it should be noted that some of our queues are configured to use “optimal” instance types, which means that they are provisioned with the tiniest instances possible. On the other hand, we have queues that are using instances as big as x1.16xlarge to run heavy jobs. The freedom of choosing the right instance type for a job is a great advantage for us.
In a few words, we can say Batch is great for orchestration. The platform enables you to provision your tasks the way you like on the platform you like with a very short delay.
Challenges
Using Batch was not free of troubles for us. Just like any other technology, we had some challenges that we needed to overcome. We feel it is best to keep the conversation honest and mention the drawbacks of this technology as well.
Monitoring
We submit millions of jobs and keeping track of them is a big challenge for us. Just finding the job that caused trouble or searching the jobs to find out the status of a situation when things are not going as planned is not possible using the AWS Batch console. That made us develop our tooling around it.
Out of instance on the spot market
Some of our queues are using certain instance types. It happened before that the instance type is not available all of a sudden. It is possible that other customers of AWS are provisioning those instance types or that certain issues are happening across the data centers. The reason is usually not transparent to us. Whatever the cause is, we would then need to find other available instance types. That hunt is not easy, and we were only able to solve it using try and error.
The instance-type shortage does not happen often. Normally, we have cases like that once every three months or so. We have disclosed the problem with the Spot team, and they said they are working on a product to resolve it.
Disk cleanup
Normally the life span of instances on Batch is very limited: The instances are provisioned, a docker image is being deployed, a job would be launched, and the instance would be terminated right after. However, since we send so many jobs to the queues, we have cases where instances would be alive for a long time serving tens of different. kinds of jobs. If a job does not do efficiently clean up its temporary files, the next job may fail because of a disk shortage issue.
The way we have worked around this problem was to bake our own AMIs with logic to cleanup aggressively for dangling docker images and unused volumes. The cleanup would make sure the current job has enough disk space to run. This simple change has resolved the problem for us.
Manual work for Map/Reduce jobs
There are some frameworks for big data processing such as Spark and Hadoop. For machine learning, there are frameworks for training like SageMaker. When using those tools, you only need to write the map/reduce logic and the framework handles the boilerplate code to scale as needed. On Batch, however, the framework is only handling the orchestration for you. That can be an advantage or a disadvantage. In some applications, that can be considered an advantage, since you can be in control of every detail. But, sometimes having to focus so much on the details can be counterproductive.
Some frameworks like Hadoop would provide a file system (i.e. HDFS) to process the big data. When using batch, you can use S3 or Lustre to handle the shared storage.
Managed queues
Each queue on Batch can be Managed or Unmanaged. For unmanaged queues, you would need to handle the scaling yourself, which is very tricky. We do use Managed queues. For them, AWS handles the scaling of the underlying ECS cluster transparently. There is an issue, though. Batch sets the desired vCPUs for each queue, and in our experience, it takes a while for the queue to catch up with the provided load.
To solve this problem, we have added some logic to BatchiePatchie to set the minimum vCPUs required to run all active jobs. This way the queue handles the scaling much faster.
Batchiepatchie
Since we started using Batch in 2017, we had some issues with it. During HackWeek, our engineers decided to take a shot at making life easier for themselves. They started working on a project to report the jobs in a way that makes more sense for us. Lorenzo Hernandez came up with the idea, and Mikko Juola suggested the name Batchiepatchie. It is a funny name, but it provides a serious service.
Mikko spent another hack week to take Batchiepatchie to next level and made it opensource. It is now available on GitHub to download. In this section, we are going to review the main functionalities of this software.
Monitoring
We already mentioned that one of our challenges with Batch is monitoring. Since our data pipeline consists of several jobs that modify and transform data in several ways, monitoring is a big challenge.
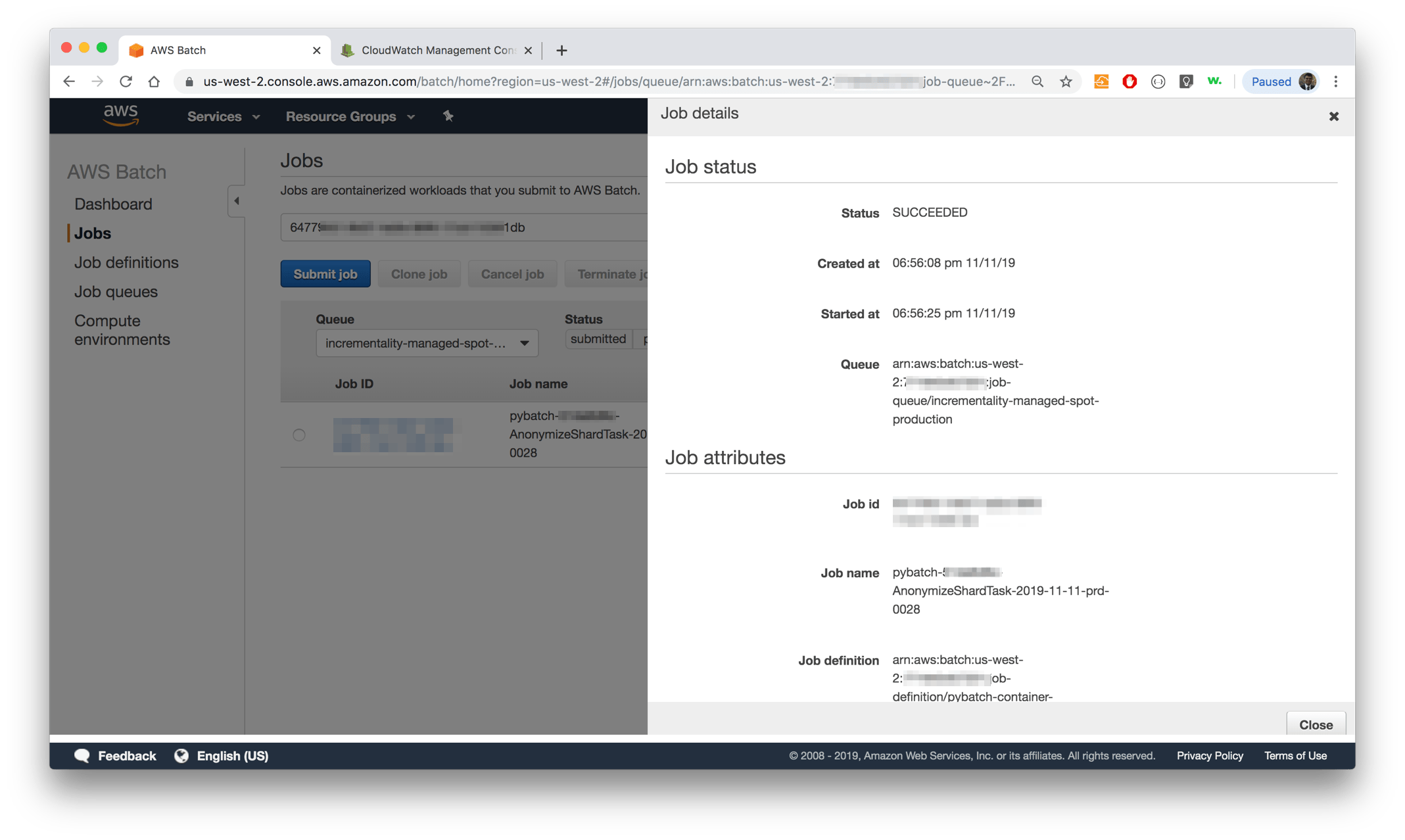
The AWS Batch console provides some views. You can review the job queues and computation environment. Because of queue activity, it takes a while for the Batch dashboard to load, and when it loads, it can only show certain jobs, and in different views. Batchiepatchie, however, shows the granular status of the jobs in a single view. For instance, if you have submitted 30 jobs, 20 of them succeeded, 5 of them are running and 5 failed, you can see all of them in a consolidated place.
In the screenshot below, you can see both the AWS Batch console and batchiepatchie snapshot for the same job queue.
 |  |
Logs
Batch only recently (as in 2019) has added a feature that allows us to review the logs of jobs. Using a job-id, Batch console would provide a link to Cloudwatch where logs would be available. As useful as that feature is, it has several shortcomings:
- When scrolling up and down, you need to wait for logs to be loaded
- In the log window, you do not have access to job details
- Searching in the logs is not easy
Batchiepatchie has been written by developers for developers. It provides all the logs generated by the process in one view which can be scrolled and searched easily. The exceptions and errors are also easily accessible.
In the screenshots below, the views of the Batch console and Batchiepatchie logs view for comparison:
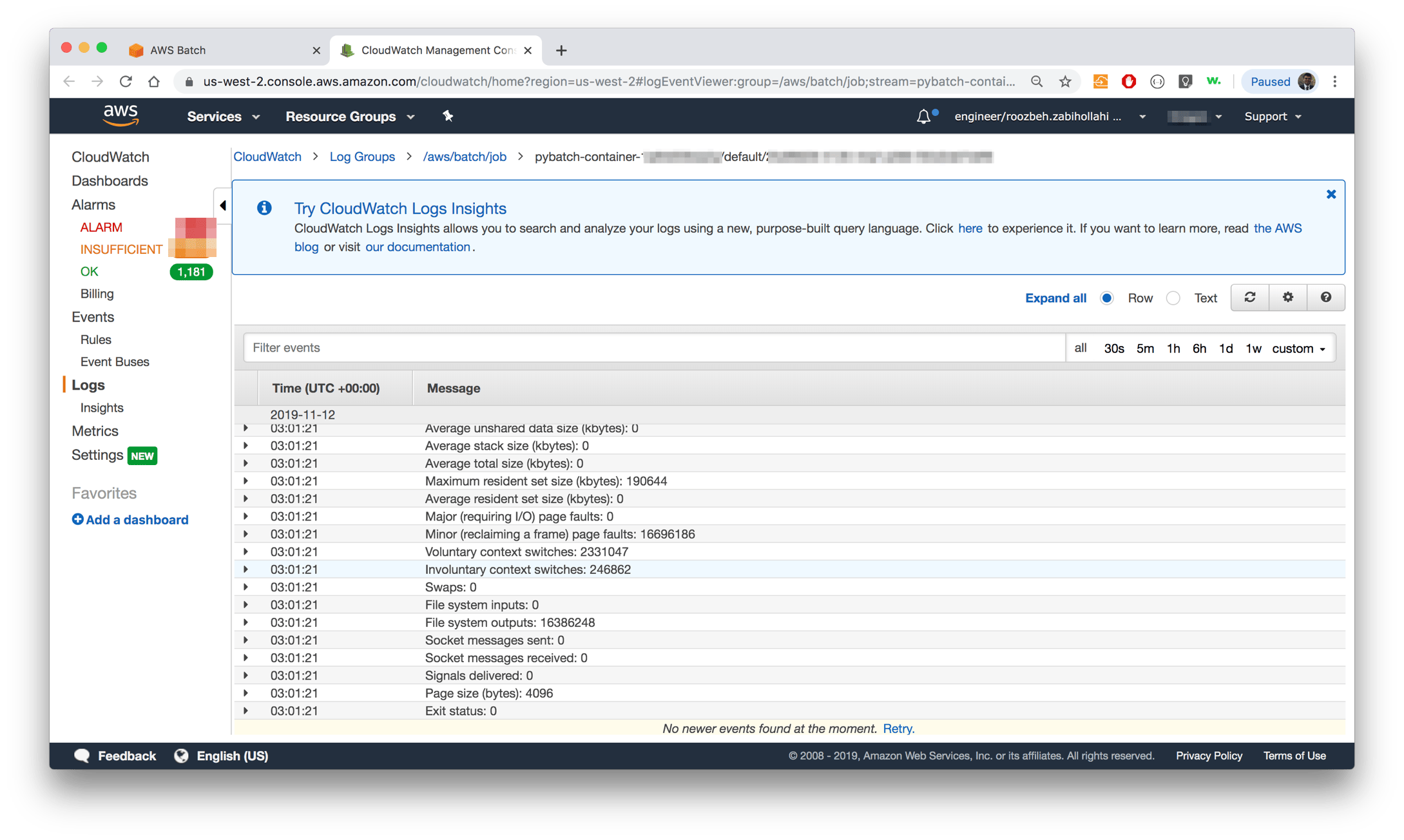 |  |
Search
Jobs can be searched by job-id in the AWS Batch console. If you happen to have job-id, you could access the job details and logs through the console. However, to find the job-id of the jobs that were submitted before, you need to go through some digging. Most of the time, we know the job name or the command line of the job that we are interested to check. That’s when Batchipatchie’s search feature is most useful.
When you type a keyword in the search bar, Batchiepatchie would look through all the fields including job name and command line of the job to list the jobs that have been submitted before or that are running at the moment. Check the screenshots below for comparison.
 |  |
Holistic view
In the recent HackWeek, in 2019, Joey has added a functionality to show the flow of jobs in queues. In the stats view, the number of jobs that have certain properties has been counted and portraited. This is very useful to have a glance of the queue status and see what is happening overall.
In the screenshot below, you can see the number of jobs that failed during the week. Just by looking at the chart, you can tell something was going on during October 16th. This could be helpful to catch silent failures or troubleshoot errors.
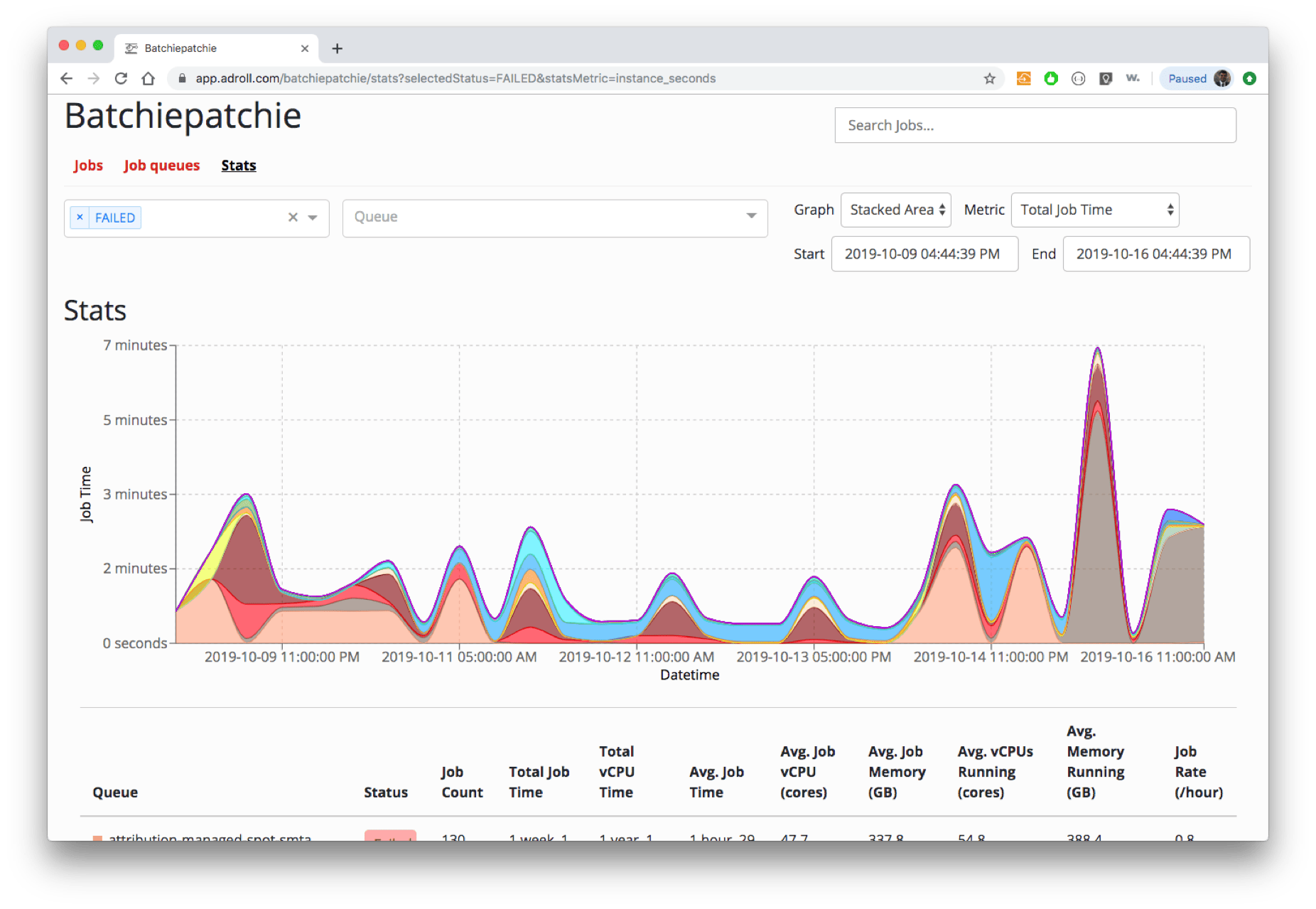
Cost Analysis
AWS Cost explorer would provide a lot of breakdowns for costs on AWS usage. By tagging different queues, you can query the cost for each queue separately. The cost of each job is not provided, however. To find out what is the most costly job in our day-to-day usage, we are using Batchiepatchie’s database.
Batchiepatchie stores all status data for jobs and instances on a PostgreSQL database. The data that is not available in the UI could be queried on the database itself. Using queries, we can estimate the dollar cost of each job.
A list of tables in that database has been listed below.
batchiepatchie=> \d+
List of relations
Name | Type | Owner | Size
------------------------------+----------+----------------+-----------
activated_job_queues | table | batchiepatchie | 16 kB
compute_environment_event_log | table | batchiepatchie | 381 MB
goose_db_version | table | batchiepatchie | 40 kB
goose_db_version_id_seq | sequence | batchiepatchie | 8192 bytes
instance_event_log | table | batchiepatchie | 28 GB
instances | table | batchiepatchie | 1537 MB
job_status_events | table | batchiepatchie | 40 kB
job_summary_event_log | table | batchiepatchie | 296 MB
jobs | table | batchiepatchie | 25 GB
task_arns_to_instance_info | table | batchiepatchie | 2452 MB
(10 rows)
If you use AWS Batch, you should check out Batchiepatchie! And if you use Batchiepatchie, please share your experience with us. We would appreciate any contribution to this repo and would love to hear from you.