Build a simple distributed system using AWS Lambda, Python, and DynamoDB
We have implemented a number of systems in support of our Erlang-based real-time bidding platform. One of these is a Celery task system which runs code implemented in Python on a set of worker instances running on Amazon EC2.
With the recent announcement of built-in support for Python in AWS Lambda functions (and upcoming access to VPC resources from Lambda), we’ve started considering increased use of Lambda for a number of applications.
In this post, we’ll present a complete example of a data aggregation system using Python-based Lambda functions, S3 events, and DynamoDB triggers; and configured using the AWS command-line tools (awscli) wherever possible. (Note: Some of these steps are handled automatically when using the AWS console.)
Here’s how our completed system will look:

Why?
Each of our EC2 instances participating in RTB maintains a set of counter values: these represent the health of an important aspect of our platform. Each instance reports these values using Kinesis, and also periodically uploads its set of counters to a per-instance key on S3 as part of a failsafe system. When we aggregate these counter values, we have greater insight into whether our system as a whole is healthy (and we can take action automatically when it isn’t). This post will focus on a system which can process the data we upload to S3.
Here’s what we actually want to do with our per-instance counters:
-
Have an up-to-date global view of total summed counter values across all instances.
-
Take action whenever the summed counter values change.
Current solution
One of our Celery tasks (A) implements counter aggregation, with the output consumed by a periodic downstream task (B) implementing our business logic. Every few minutes, task A does the following:
-
Scans an S3 bucket prefix for keys having a certain naming convention. (Each of these keys represents counter data uploaded by a single EC2 instance, and each key name includes the current date and the ID of the instance which uploaded it. An instance usually writes to the same key.)
-
Reads the contents of all these keys, which have a format like the following:
COUNTER1 VALUE1 COUNTER2 VALUE2 COUNTER3 VALUE3
-
Sums all the values for each counter. (The same counter can appear in multiple files.)
-
Writes the summed counter values to a single S3 key for use in task B, which can then take action on the aggregate counter values.
Drawbacks of current solution
We’re essentially polling S3 to detect file changes, and we’re also reprocessing data which has not necessarily changed. This is time-consuming and ties up resources which could have been allocated elsewhere.
It also would be nice to react more quickly to updated counter values. With our current implementation, there can be significant lag between a counter data upload and actually observing its contribution to the global aggregate value.
Enter Lambda
Lambda promises scalable, serverless, event-based code execution with granular billing. This is a compelling value proposition for the following reasons:
-
Standalone code bundles are the unit of deployment;
-
We can run our code while only paying for the time spent actually executing it instead of spending money on idle CPU time;
-
We can reduce the peak load experienced by our task system (by migrating certain frequent and spiky tasks to Lambda), allowing us to reduce the amount of resources allocated to it while increasing utilization of the remaining resources;
-
Our counter system will perform its work in a more timely manner by responding to events instead of scanning S3, and it will avoid reprocessing data which has not changed.
Using Lambda is now much easier thanks to the recently-announced built-in support for Python. (Note: it has always been possible to run Python-based code, but now it’s easier to get started.)
System design
We want a system which can react to S3 events, process and aggregate data associated with those events, and eventually convey some processed data back to S3 after executing some business logic.
Cost comparison
We can do all of this using Lambda, but should we? Let’s do a rough cost estimate assuming we have 100 instances each uploading to S3 a file containing 100 counters every 60 seconds.
Original system
Suppose (1) we created our task system only to support our two tasks A and B, (2) that we scan S3 every five minutes, (3) that task A completes in 60 seconds, and (4) that we deploy four times.
We might then have the following costs:
| Description | Cost |
|---|---|
| task scheduler (t2.micro) | $0.013 / hour |
| task worker (m3.medium) | $0.067 / hour |
| S3 usage | negligible |
| design/configure/test/deploy task infrastructure | 16 hours |
| design/test this task | 4 hours |
| deploy this task | 0.5 hours / deploy |
| infrastructure maintenance | 1 hour / month |
| Initial developer time | 22 hours |
| Ongoing developer time | 12 hours / year |
| Recurring costs | $701 / year |
| Reaction time | 1 to 6 minutes |
Lambda-based system
We’ll assume the following for our Lambda-based implementation:
-
100 files are uploaded to S3 every 60 seconds, each containing 100 counters. We want all data to be processed within 50 seconds.
-
We’ll write counter values to a DynamoDB table. To support 10,000 writes over 50 seconds, we’ll need 200 units of provisioned write capacity. We assume our library (boto3) will handle retries and spread out our writes when we exceed our provisioned write capacity and burst limits.
-
To support the implementation described later in this post, we’ll have a second table which is updated as a result of each change made to the first. This second table therefore will also need 200 units of provisioned write capacity. It will be updated by a second Lambda function (which we assume has the same characteristics as the first) triggered by events on a DynamoDB stream.
-
We’ll need to create some packaging / testing / deployment helper scripts to deploy our code.
| Description | Cost |
|---|---|
| (table 1) provision 200 DynamoDB writes/sec | $0.13 / hour |
| (table 2) provision 200 DynamoDB writes/sec | $0.13 / hour |
| (table 1 stream) 200 GetRecords/sec (worst case) | negligible |
| Lambda invocation cost | negligible |
| Lambda duration cost @ 1536 MB, 2 * 100 * 50000 ms (worst case) | $0.25 / hour |
| design/test Lambda deployment scripts | 4 hours |
| design/test needed Lambda functions | 4 hours |
| deploy needed Lambda functions | 5 minutes / deploy |
| infrastructure maintenance | $0 |
| Initial developer time | 8 hours |
| Ongoing developer time | 20 minutes / year |
| Recurring costs (DynamoDB) | $2279 / year |
| Recurring costs (Lambda) | $2192 / year |
| Reaction time | 0.1 to 51 seconds |
Worth it? Possibly.
-
We’ve greatly improved the upper (7x) and lower (600x) bounds for hypothetical system reaction time (length of time after a file upload before we can start observing its effects). With the Lambda-based system, we start updating our stored state in DynamoDB as soon as our function begins executing.
-
Less developer time is required to get a working system. The original design requires almost 3x initial developer time, and almost 40x ongoing time to maintain. The Lambda solution saves 3 developer-days of time in the first year.
-
More money is required on an ongoing basis—around 6.5x—but we don’t have to manage any infrastructure, which leaves more time for other projects.
-
It’s easier to scale (up to a point):
-
If we wanted to halve our maximum reaction time, we could double our provisioned DynamoDB write capacity without changing anything else. (This would double our DynamoDB costs and halve our worst-case Lambda costs, for a total recurring cost increase of 26%.)
-
If our RTB system were to suddenly double in size, we could simply double our provisioned write capacity using the console without exploring alternate designs or modifying our infrastructure!
-
There’s More Than One Way To Do It™
We could take a different approach which (1) doesn’t involve Lambda or DynamoDB, or (2) uses these services in a different way. This cost estimate shows that using Lambda for a system like the one described here is within the realm of possibility.
Eventual consistency
Working with distributed systems requires balancing trade-offs. It’s worth noting that the Lambda-based system we describe exhibits eventual consistency: the state we can observe at any particular moment in time may not yet include all updates we’ve made, but all updates will eventually be observable if we stop performing them. This is due to the use of DynamoDB and S3 as well as the system’s overall design.
-
DynamoDB supports eventually-consistent reads (the default) as well as strongly-consistent reads. The consistency time scale is relatively small (usually “within one second”) compared to other parts of our system. Whenever we read an item, we’ll observe a state which is the result of some sequence of atomic updates (but not necessarily all of the most recent updates). We can live with this trade-off.
-
S3 supports eventual consistency for overwritten objects, and the typical consistency time scale is again relatively small—on the order of seconds. We shouldn’t need to worry about it as long as we don’t receive out-of-order event notifications for the same key: we’ll always read data which was valid at one point in time, and we can check timestamps and versions if we’re concerned about stale events or reads.
Our system as a whole wouldn’t be strongly-consistent even if S3 and DynamoDB presented only strongly-consistent interfaces, as we can observe our system’s output (contents of second DynamoDB table) before all current input (S3 file uploads) has been processed. We essentially have a view of an atomic update stream which periodically will be a few seconds out of date; this is fine for our purposes.
Implementation
Enough background—let’s implement our system!
We need to react to S3 file uploads. We can configure our S3 bucket to emit events which will cause a Lambda function to run. Our first new component will therefore look like this:

SNS topic creation
We’ll create an SNS topic to receive S3 events. While Lambda directly supports S3 events, using an SNS topic will allow us to more easily configure additional S3 event handlers in the future for events having the same prefix. (S3 doesn’t currently support event handlers dispatching on prefixes which overlap.)
REGION="us-west-2"
BUCKET="your-bucket-name"
TOPIC_NAME="your-file-upload-topic"
SOURCE_ARN="arn:aws:s3:::$BUCKET"
# creating a topic gives us its ARN. we'll need that later along with
# our account number:
TOPIC_ARN=$(aws sns create-topic \
--region $REGION \
--name $TOPIC_NAME \
--output text \
--query 'TopicArn')
ACCOUNT=$(echo $TOPIC_ARN | awk -F':' '{print $5}')We also need to configure the SNS topic’s policy to allow our S3 bucket to publish events to it:
POLICY=$(python -c "import json; print json.dumps(
{'Version': '2008-10-17',
'Id': 'upload-events-policy',
'Statement': [
{'Resource': '$TOPIC_ARN',
'Effect': 'Allow',
'Sid': 'allow_s3_publish',
'Action': 'SNS:Publish',
'Condition': {'ArnEquals': {'aws:sourceArn': '$SOURCE_ARN'}},
'Principal': '*'},
{'Resource': '$TOPIC_ARN',
'Effect': 'Allow',
'Sid': 'owner_sns_permissions',
'Action': ['SNS:Subscribe', 'SNS:ListSubscriptionsByTopic',
'SNS:DeleteTopic', 'SNS:GetTopicAttributes',
'SNS:Publish', 'SNS:RemovePermission',
'SNS:AddPermission', 'SNS:Receive',
'SNS:SetTopicAttributes'],
'Condition': {'StringEquals': {'AWS:SourceOwner': '$ACCOUNT'}},
'Principal': {'AWS': '*'}}
]})")
aws sns set-topic-attributes \
--region $REGION \
--topic-arn "$TOPIC_ARN" \
--attribute-name "Policy" \
--attribute-value "$POLICY"S3 bucket configuration
We need to configure our S3 bucket to publish events to the topic. If any event settings already exist for the bucket, we should instead do this in the S3 console:
# we're interested in events occurring under this prefix:
PREFIX="path/to/data/"
# we don't want to accidentally overwrite an existing event
# configuration:
EXISTING=$(aws s3api get-bucket-notification-configuration \
--bucket $BUCKET)
if [ -z "$EXISTING" ]; then
# there was no existing configuration. install our new one:
EVENT_CONFIG=$(python -c "import json; print json.dumps(
{'TopicConfigurations': [
{ 'Id': '$TOPIC_NAME events',
'TopicArn': '$TOPIC_ARN',
'Events': ['s3:ObjectCreated:*'],
'Filter': {
'Key': { 'FilterRules': [
{ 'Name': 'prefix', 'Value': '$PREFIX' }
]}
}
}]})")
aws s3api put-bucket-notification-configuration \
--bucket $BUCKET \
--notification-configuration "$EVENT_CONFIG"
else
echo "bucket already has an event configuration."
echo "use the S3 console to configure events."
fiLambda function creation
We need to choose a name for our first Lambda function, create a role to use when executing, and enable AWS Lambda to assume that role so it can actually execute our function:
FUNCTION1_NAME="counter-upload-processor"
ASSUMEROLE_POLICY=$(python -c "import json; print json.dumps(
{ 'Version': '2012-10-17',
'Statement': [{ 'Sid': '',
'Effect': 'Allow',
'Principal': {'Service': 'lambda.amazonaws.com'},
'Action': 'sts:AssumeRole'
}] })")
ROLE1_NAME="$FUNCTION1_NAME-execute"
# create the execution role and save its ARN for later:
EXEC_ROLE1_ARN=$(aws iam create-role \
--region $REGION \
--role-name "$ROLE1_NAME" \
--assume-role-policy-document "$ASSUMEROLE_POLICY" \
--output text \
--query 'Role.Arn')Lambda functions normally emit logs using CloudWatch to a log group whose name is derived from the function’s name. Let’s create a log group for our function:
LOG_GROUP1="/aws/lambda/$FUNCTION1_NAME"
aws logs create-log-group \
--region $REGION \
--log-group-name "$LOG_GROUP1"To actually emit logs, we need to grant some permissions to the role used by our Lambda function:
CLOUDWATCH_POLICY1=$(python -c "import json; print json.dumps(
{ 'Version': '2012-10-17',
'Statement': [
{ 'Effect': 'Allow',
'Action': ['logs:PutLogEvents',
'logs:CreateLogStream'],
'Resource': 'arn:aws:logs:$REGION:$ACCOUNT:log-group:$LOG_GROUP1:*' }
]})")
aws iam put-role-policy \
--region $REGION \
--role-name "$ROLE1_NAME" \
--policy-name "emit-cloudwatch-logs" \
--policy-document "$CLOUDWATCH_POLICY1"We can now create a Python Lambda function. This naming convention and zip file layout will allow it to be edited using the AWS Lambda console:
cat >lambda_function.py <<EOF
import logging
def lambda_handler(event, context):
logging.getLogger().setLevel(logging.INFO)
logging.info('got event: {}'.format(event))
logging.info('got context: {}'.format(context))
return False
EOF
zip -j lambda-example-1.zip lambda_function.py
# we'll need the function ARN later:
FUNCTION1_ARN=$(aws lambda create-function \
--region $REGION \
--runtime python2.7 \
--role "$EXEC_ROLE1_ARN" \
--description "counter file reverse mapper" \
--timeout 10 \
--memory-size 128 \
--handler lambda_function.lambda_handler \
--zip-file fileb://lambda-example-1.zip \
--function-name $FUNCTION1_NAME \
--output text \
--query 'FunctionArn')Let’s manually test the function:
aws lambda invoke \
--region $REGION \
--function-name $FUNCTION1_ARN \
--payload '{}' \
--log-type 'Tail' \
--output text \
--query 'LogResult' \
- \
| base64 --decodeThe result should look like this:
START RequestId: e7739dcd-7380-11e5-aa63-c740254a89b5 Version: $LATEST
[INFO] 2015-11-16T21:08:38.830Z e7739dcd-7380-11e5-aa63-c740254a89b5 got event {}
[INFO] 2015-11-16T21:08:38.830Z e7739dcd-7380-11e5-aa63-c740254a89b5 got context <__main__.LambdaContext object at 0x7f61bfd246d0>
END RequestId: e7739dcd-7380-11e5-aa63-c740254a89b5
REPORT RequestId: e7739dcd-7380-11e5-aa63-c740254a89b5 Duration: 0.41 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 13 MB
Putting it all together
We now have a working Lambda function implemented in Python. We can subscribe it to the SNS topic we created earlier:
aws sns subscribe \
--region $REGION \
--protocol lambda \
--topic-arn $TOPIC_ARN \
--notification-endpoint $FUNCTION1_ARNBut before things will actually work, we need to grant the SNS topic permission to invoke our Lambda function:
aws lambda add-permission \
--region $REGION \
--function-name $FUNCTION1_ARN \
--statement-id "$FUNCTION1_NAME-invoke" \
--principal "sns.amazonaws.com" \
--action "lambda:InvokeFunction" \
--source-arn $TOPIC_ARNAs objects are uploaded to our S3 bucket, we should start seeing records of invocations and logs appearing in the CloudWatch log group we created earlier. Let’s upload a test file:
echo "COUNTER1 12345" \
| aws s3 cp - s3://$BUCKET/${PREFIX}$(date +'%Y-%m-%d')/values_i-deadbeefWe can view our CloudWatch logs from the command line. We should see some output corresponding to the key we just uploaded:
for STREAM_NAME in $(aws logs describe-log-streams \
--region $REGION \
--log-group-name $LOG_GROUP1 \
--descending \
--order-by 'LastEventTime' \
--output text \
--query 'logStreams[].logStreamName'); do
aws logs get-log-events \
--region $REGION \
--log-group-name $LOG_GROUP1 \
--log-stream-name $STREAM_NAME \
--start-from-head \
--output text \
--query 'events[].message'
doneIf you see something like this, it worked:
[INFO] 2015-11-16T23:44:15.876Z 1ad60ef6-3417-12c5-92b0-0f211eba5fc1 got event: {u'Records': [{u'EventVersion': u'1.0', u'EventSubscriptionArn': ... u'EventSource': u'aws:sns', u'Sns': { ... u'Message': u'{"Records":[{"eventVersion":"2.0","eventSource":"aws:s3", ...
Data persistence
Our Lambda function is now hooked up to events emitted from S3! However, it doesn’t yet do anything useful. We want our system to react to events and to only reprocess data which has changed. We’ll achieve this by (1) storing some intermediate state in DynamoDB and (2) using a second Lambda function to process updates to this state.
Our updated system will look like this:

Create a DynamoDB table
We want to store items which look like this in our intermediate state table:
{ 'Counter': { 'S': 'XXXXXXXXXXXXXXXXXXXXXX' },
'Date': { 'S': 'YYYY-MM-DD' },
'InstanceValues': { 'M': { 'i-deadbeef': { 'N': '1234' },
'i-beefdead': { 'N': '5678' },
...
}
}
}
Using a map type (“M”) and document paths to store per-instance counter values will allow concurrently-executing Lambda function invocations to update the same DynamoDB item without interfering with each other.
Our table schema will look like this:
TABLE="$FUNCTION1_NAME-state"
aws dynamodb create-table \
--region $REGION \
--table-name $TABLE \
--provisioned-throughput ReadCapacityUnits=10,WriteCapacityUnits=10 \
--key-schema AttributeName=Counter,KeyType=HASH \
AttributeName=Date,KeyType=RANGE \
--attribute-definitions AttributeName=Counter,AttributeType=S \
AttributeName=Date,AttributeType=SS3-SNS event handling
We want to update our intermediate state whenever an event comes in. Our SNS events will look like this:
{"Records": [
{"EventVersion": "1.0",
"EventSubscriptionArn": "SUBSCRIPTION_ARN",
"EventSource": "aws:sns",
"Sns": {
"SignatureVersion": "1",
"Timestamp": "2015-11-16T22:08:36.726Z",
"Signature": "SIG_DATA",
"SigningCertUrl": "SIG_CERT_URL",
"MessageId": "MESSAGE_ID",
"Message": "JSON_MESSAGE_DATA",
"MessageAttributes": {},
"Type": "Notification",
"UnsubscribeUrl": "UNSUBSCRIBE_URL",
"TopicArn": "$TOPIC_ARN",
"Subject": "Amazon S3 Notification"
}
}
]}The JSON_MESSAGE_DATA value in these events will be a json-encoded S3 event. It will look like this when decoded:
{"Records": [
{"eventVersion": "2.0",
"eventTime": "2015-11-16T22:08:36.682Z",
"requestParameters": {"sourceIPAddress": "1.2.3.4"},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "$TOPIC_NAME events",
"object": {"versionId": "NEW_OBJECT_VERSION_ID",
"eTag": "NEW_OBJECT_ETAG",
"sequencer": "SEQUENCER_VALUE",
"key": "${PREFIX}2015-11-16/values_i-deadbeef",
"size": 16},
"bucket": { "arn": "$SOURCE_ARN",
"name": "$BUCKET",
"ownerIdentity": {"principalId": "OWNING_PRINCIPAL_ID"}
}},
"responseElements": { "x-amz-id-2": "AMZ_ID_1",
"x-amz-request-id": "AMZ_ID_2" },
"awsRegion": "$REGION",
"eventName": "ObjectCreated:Put",
"userIdentity": {"principalId": "CREATING_PRINCIPAL_ID"},
"eventSource": "aws:s3"
}
]}(Note: the key value in the event is url-encoded.)
Let’s update the code in lambda_function.py to process these events:
import logging, boto3, botocore.exceptions, json, urllib
TABLE = "counter-upload-processor-state"
FILENAME_PREFIX = 'values_'
def lambda_handler(event, context):
logging.getLogger().setLevel(logging.INFO)
for record in event['Records']:
if 'aws:sns' == record['EventSource'] and record['Sns']['Message']:
handle_sns_event(json.loads(record['Sns']['Message']), context)
return True
def handle_sns_event(event, context):
for record in event['Records']:
logging.info('looking at {}'.format(record))
if 'aws:s3' == record['eventSource'] \
and record['eventName'].startswith('ObjectCreated:'):
region = record['awsRegion']
bucket_name = record['s3']['bucket']['name']
key_name = urllib.unquote(record['s3']['object']['key'])
key_vsn = record['s3']['object'].get('versionId')
logging.info('new object: s3://{}/{} (v:{})'.format(bucket_name,
key_name,
key_vsn))
key = boto3.resource('s3', region_name=region) \
.Bucket(bucket_name) \
.Object(key_name)
data = key.get(**{'VersionId': key_vsn} if key_vsn else {})
process_key(region, key, data, context)
def process_key(region, key, data, context):
filename = key.key.split('/')[-1]
if filename.startswith(FILENAME_PREFIX):
date = key.key.split('/')[-2]
instance_id = filename.split('_')[1]
logging.info('processing ({}, {})'.format(date, instance_id))
for line in data['Body'].read().splitlines():
counter, value = [x.strip() for x in line.split()]
update_instance_value(region, date, instance_id, counter, value)
def update_instance_value(region, date, instance_id, counter, value):
logging.info('updating instance counter value: {} {} {}'.format(
instance_id, counter, value))
tbl = boto3.resource('dynamodb', region_name=region) \
.Table(TABLE)
key = {'Counter': counter,
'Date': date}
# updating a document path in an item currently fails if the ancestor
# attributes don't exist, and multiple SET expressions can't
# (currently) be used to update overlapping document paths (even with
# `if_not_exists`), so we must first create the `InstanceValues` map
# if needed. we use a condition expression to avoid needlessly
# triggering an update event on the stream we'll create for this
# table. in a real application, we might first query the table to
# check if these updates are actually needed (reads are cheaper than
# writes).
lax_update(tbl,
Key=key,
UpdateExpression='SET #valuemap = :empty',
ExpressionAttributeNames={'#valuemap': 'InstanceValues'},
ExpressionAttributeValues={':empty': {}},
ConditionExpression='attribute_not_exists(#valuemap)')
# we can now actually update the target path. we only update if the
# new value is different (in a real application, we might first query
# and refrain from attempting the conditional write if the value is
# unchanged):
lax_update(tbl,
Key=key,
UpdateExpression='SET #valuemap.#key = :value',
ExpressionAttributeNames={ '#key': instance_id,
'#valuemap': 'InstanceValues'},
ExpressionAttributeValues={':value': int(value)},
ConditionExpression='NOT #valuemap.#key = :value')
def lax_update(table, **kwargs):
try:
return table.update_item(**kwargs)
except botocore.exceptions.ClientError as exc:
code = exc.response['Error']['Code']
if 'ConditionalCheckFailedException' != code:
raiseWe can now update our Lambda function’s code:
zip -j lambda-example-2.zip lambda_function.py
aws lambda update-function-code \
--region $REGION \
--function-name $FUNCTION1_ARN \
--zip-file fileb://lambda-example-2.zipBefore this updated code will work, we need to grant permission to the execution role we created earlier for our Lambda function—otherwise, it won’t be able to access our S3 bucket or update our DynamoDB table:
REV_MAPPER_POLICY=$(python -c "import json; print json.dumps(
{ 'Version': '2012-10-17',
'Statement': [
{ 'Effect': 'Allow',
'Action': ['dynamodb:UpdateItem'],
'Resource': 'arn:aws:dynamodb:$REGION:$ACCOUNT:table/$TABLE' },
{ 'Effect': 'Allow',
'Action': ['s3:GetObject',
's3:GetObjectVersion'],
'Resource': '$SOURCE_ARN/${PREFIX}*' }
]})")
aws iam put-role-policy \
--region $REGION \
--role-name "$ROLE1_NAME" \
--policy-name "fetch-data-and-update-dynamo" \
--policy-document "$REV_MAPPER_POLICY"As new files appear in our bucket under the target prefix, we should see our table being updated accordingly. Let’s give it a try:
echo "COUNTER1 12345" \
| aws s3 cp - s3://$BUCKET/${PREFIX}$(date +'%Y-%m-%d')/values_i-deadbeef
echo "COUNTER1 12345" \
| aws s3 cp - s3://$BUCKET/${PREFIX}$(date +'%Y-%m-%d')/values_i-beefdead
echo "COUNTER1 54321
COUNTER2 54321" | aws s3 cp - s3://$BUCKET/${PREFIX}$(date +'%Y-%m-%d')/values_i-foobazzledIf we scan our intermediate state table, we should now see that it has been updated by our Lambda function:
aws dynamodb scan \
--region $REGION \
--table-name $TABLE
{
"Count": 2,
"Items": [
{
"Date": {
"S": "2015-11-16"
},
"InstanceValues": {
"M": {
"i-foobazzled": {
"N": "54321"
}
}
},
"Counter": {
"S": "COUNTER2"
}
},
{
"Date": {
"S": "2015-11-16"
},
"InstanceValues": {
"M": {
"i-beefdead": {
"N": "12345"
},
"i-deadbeef": {
"N": "12345"
},
"i-foobazzled": {
"N": "54321"
}
}
},
"Counter": {
"S": "COUNTER1"
}
}
],
"ScannedCount": 2,
"ConsumedCapacity": null
}If you see something like this, it worked. Huzzah! We’ve completed the first part of our system:
Enter DynamoDB Streams
In our intermediate state table we’re now maintaining an inverted map of the original data uploaded to S3, converting per-instance lists of per-counter values on S3 to per-counter lists of per-instance values in DynamoDB. Our goal is to sum up all per-instance values for each counter and to take action when these values exceed a per-counter limit, only processing data which has changed.
DynamoDB Streams is a recently-released feature which grants a view of change events on a DynamoDB table (akin to a Kinesis stream). We can use “DynamoDB Triggers” (the combination of DynamoDB Streams and Lambda functions) to achieve our goal.
The current version of the awscli tools doesn’t support enabling or modifying DynamoDB stream settings, so for now we must use the console to configure a table stream:

Since we’ll be performing an operation on the entire new value of updated items, select “new image” as the stream view type:

After configuring the table stream in the DynamoDB console, we can fetch its ARN:
STREAM_ARN=$(aws dynamodbstreams list-streams \
--region $REGION \
--table-name $TABLE \
--query 'Streams[0].StreamArn' \
--output text)Putting it all together (again)
We’ll need another Lambda function to process change events on our state table. We’ll use the same recipe (and initial code) as our first Lambda function.
Here’s how the next stage of our system will look:

FUNCTION2_NAME="counter-upload-aggregator"
ROLE2_NAME="$FUNCTION2_NAME-execute"
EXEC_ROLE2_ARN=$(aws iam create-role \
--region $REGION \
--role-name "$ROLE2_NAME" \
--assume-role-policy-document "$ASSUMEROLE_POLICY" \
--output text \
--query 'Role.Arn')
LOG_GROUP2="/aws/lambda/$FUNCTION2_NAME"
aws logs create-log-group \
--region $REGION \
--log-group-name "$LOG_GROUP2"
CLOUDWATCH_POLICY2=$(python -c "import json; print json.dumps(
{ 'Version': '2012-10-17',
'Statement': [
{ 'Effect': 'Allow',
'Action': ['logs:PutLogEvents',
'logs:CreateLogStream'],
'Resource': 'arn:aws:logs:$REGION:$ACCOUNT:log-group:$LOG_GROUP2:*' }
]})")
aws iam put-role-policy \
--region $REGION \
--role-name "$ROLE2_NAME" \
--policy-name "emit-cloudwatch-logs" \
--policy-document "$CLOUDWATCH_POLICY2"
FUNCTION2_ARN=$(aws lambda create-function \
--region $REGION \
--runtime python2.7 \
--role "$EXEC_ROLE2_ARN" \
--description "counter data aggregator" \
--timeout 10 \
--memory-size 128 \
--handler lambda_function.lambda_handler \
--zip-file fileb://lambda-example-1.zip \
--function-name $FUNCTION2_NAME \
--output text \
--query 'FunctionArn')We need to grant some additional permissions to allow access to our table stream:
STREAM_POLICY=$(python -c "import json; print json.dumps(
{ 'Version': '2012-10-17',
'Statement': [
{ 'Effect': 'Allow',
'Action': ['dynamodb:GetRecords',
'dynamodb:GetShardIterator',
'dynamodb:DescribeStream'],
'Resource': '$STREAM_ARN' },
{ 'Effect': 'Allow',
'Action': ['dynamodb:DescribeStreams'],
'Resource': '*' }
]})")
aws iam put-role-policy \
--region $REGION \
--role-name "$ROLE2_NAME" \
--policy-name "dynamodb-stream-access" \
--policy-document "$STREAM_POLICY"We can now create an event source mapping between our table stream and our new Lambda function. This will cause Lambda to poll the DynamoDB stream and execute our new function with events read from it:
aws lambda create-event-source-mapping \
--region $REGION \
--event-source-arn $STREAM_ARN \
--function-name $FUNCTION2_ARN \
--starting-position LATEST \
--enabledLet’s upload another test file. (Note: there may be a delay after configuring the event source mapping before this upload will result in the second function being triggered.)
echo "COUNTER1 123456" \
| aws s3 cp - s3://$BUCKET/${PREFIX}$(date +'%Y-%m-%d')/values_i-deadbeefThis upload should cause our first Lambda function to update the intermediate state table. Our second Lambda function should receive an event like this:
{"Records": [
{ "awsRegion": "us-east-1",
"eventName": "MODIFY",
"eventSourceARN": "$STREAM_ARN",
"eventSource": "aws:dynamodb",
"eventID": "SOME_EVENT_ID",
"eventVersion": "1.0",
"dynamodb": { "StreamViewType": "NEW_IMAGE",
"SequenceNumber": "SOME_SEQUENCE_NUMBER",
"SizeBytes": 125,
"Keys": {
"Date": {"S": "2015-11-16"},
"Counter": {"S": "COUNTER1"}
},
"NewImage": {
"Counter": {"S": "COUNTER1"},
"Date": {"S": "2015-11-16"},
"InstanceValues": {"M": {"i-foobazzled": {"N": "54321"},
"i-beefdead": {"N": "12345"},
"i-deadbeef": {"N": "123456"}}}
}
}
}
]}If we repeat the same upload, our second Lambda function should not be executed a second time—our first Lambda function only updates an item if it would result in a new or changed value. This is good, but it doesn’t quite fulfill our goal of only processing changed data: if a new instance comes online and emits a value of zero for a counter, our second Lambda function will still see an update despite the global value for that counter remaining unchanged.
Rinse and Repeat
To fulfill our goal of only acting on changed data, we’ll create a second DynamoDB table to hold actual per-counter aggregate values. (A third Lambda function monitoring this second table’s event stream could contain the business logic acting on changed counter values; all of our goals would then have been met.)
Here’s how this part of our updated system will look:
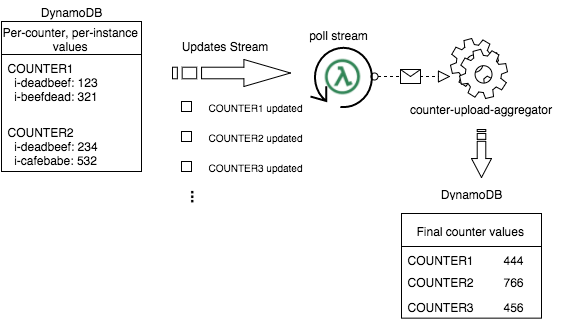
In our second table, we want to store items which look like this:
{ 'Counter': { 'S': 'XXXXXXXXXXXXXXXXXXXXXX' },
'Date': { 'S': 'YYYY-MM-DD' },
'Value': { 'N': '1234567' }
}
Our second DynamoDB table has the following schema. Including the ByDate global secondary index will allow us to query the table for all items having a particular date, which might come in handy later (although it will double our table cost, because all attributes participate in the index):
TABLE2="aggregate-counters"
aws dynamodb create-table \
--region $REGION \
--table-name $TABLE2 \
--provisioned-throughput ReadCapacityUnits=10,WriteCapacityUnits=10 \
--key-schema AttributeName=Counter,KeyType=HASH \
AttributeName=Date,KeyType=RANGE \
--attribute-definitions AttributeName=Counter,AttributeType=S \
AttributeName=Date,AttributeType=S \
--global-secondary-indexes '[{
"IndexName": "ByDate",
"KeySchema": [{ "AttributeName": "Date",
"KeyType": "HASH" }],
"ProvisionedThroughput": { "ReadCapacityUnits": 1,
"WriteCapacityUnits": 10 },
"Projection": { "ProjectionType": "ALL" }
}]'Let’s update our second Lambda function’s lambda_function.py file:
import logging, boto3, botocore.exceptions
TABLE = "aggregate-counters"
def lambda_handler(event, context):
logging.getLogger().setLevel(logging.INFO)
for record in event['Records']:
if 'aws:dynamodb' == record['eventSource'] \
and 'MODIFY' == record['eventName'] \
and 'NEW_IMAGE' == record['dynamodb']['StreamViewType']:
region = record['awsRegion']
keys = record['dynamodb']['Keys']
date = keys['Date']['S']
counter = keys['Counter']['S']
new_item = record['dynamodb']['NewImage']
instance_values = new_item['InstanceValues']['M']
total_value = sum(int(v['N'])
for v in instance_values.values())
logging.info('updated counter: {} {} {}'.format(
date, counter, total_value))
# go! thou art counted:
lax_update(boto3.resource('dynamodb', region_name=region) \
.Table(TABLE),
Key={'Counter': counter,
'Date': date},
UpdateExpression='SET #value = :value',
ExpressionAttributeNames={'#value': 'Value'},
ExpressionAttributeValues={':value': total_value},
ConditionExpression='NOT #value = :value')
return True
def lax_update(table, **kwargs):
try:
return table.update_item(**kwargs)
except botocore.exceptions.ClientError as exc:
code = exc.response['Error']['Code']
if 'ConditionalCheckFailedException' != code:
raiseAnd update our second Lambda function’s code:
zip -j lambda-example-3.zip lambda_function.py
aws lambda update-function-code \
--region $REGION \
--function-name $FUNCTION2_ARN \
--zip-file fileb://lambda-example-3.zipAs before, we need to grant permission to the execution role used by our second Lambda function so it can update our second DynamoDB table:
AGGREGATOR_POLICY=$(python -c "import json; print json.dumps(
{ 'Version': '2012-10-17',
'Statement': [
{ 'Effect': 'Allow',
'Action': ['dynamodb:UpdateItem'],
'Resource': 'arn:aws:dynamodb:$REGION:$ACCOUNT:table/$TABLE2' }
]})")
aws iam put-role-policy \
--region $REGION \
--role-name "$ROLE2_NAME" \
--policy-name "update-dynamo-aggregate-counters" \
--policy-document "$AGGREGATOR_POLICY"When we upload new counter data, our second table should be updated with the total summed value:
echo "COUNTER1 1000" \
| aws s3 cp - s3://$BUCKET/${PREFIX}$(date +'%Y-%m-%d')/values_i-flubThis upload should have triggered the following sequence of events:
-
Our S3 bucket emits an
ObjectCreatedevent to our SNS topic. -
Our topic wraps the S3 event in an SNS notification and delivers it to our first Lambda function (invoking it).
-
Our first Lambda function executes and updates our first table.
-
An event appears on our first table’s event stream, which (Lambda on behalf of) our second Lambda function has been polling.
-
Our second Lambda function executes and updates our second table.
We should see a value of 12345+123456+1000+54321 = 191122 in our second table, which is the sum of all uploaded values for COUNTER1. We haven’t updated any other counter values since setting up our second table and function, so they shouldn’t yet exist in our second table:
aws dynamodb query \
--region $REGION \
--table-name $TABLE2 \
--index-name "ByDate" \
--key-condition-expression '#date = :date' \
--expression-attribute-names '{"#date": "Date",
"#value": "Value",
"#counter": "Counter"}' \
--expression-attribute-values '{":date":
{"S": "'$(date +'%Y-%m-%d')'"}}' \
--projection-expression "#date, #counter, #value"{
"Count": 1,
"Items": [
{
"Date": {
"S": "2015-11-16"
},
"Value": {
"N": "191122"
},
"Counter": {
"S": "COUNTER1"
}
}
],
"ScannedCount": 1,
"ConsumedCapacity": null
}If you see this, it worked! Our final system:
Onward and Upward
We have successfully implemented a basic system which can count things we care about by reacting appropriately to S3 uploads. We also eliminated the need to worry about server configuration tools and management!
By implementing two simple Python modules and making some configuration calls, we have:
-
Decreased coupling between components: Instead of a set of cooperating periodic tasks, we have some small Lambda functions each doing one simple thing—reacting to events. Each is also easily testable (1) locally with a test suite, (2) in the Lambda console, and (3) from the command line using
awscli. -
Improved responsiveness and scalability: Our new system can begin reacting to updates with less latency than the original, and we can realize significant performance gains simply by deciding to spend more money—or less, if our requirements decrease—without any need for a redesign.
Overcoming Failure
The example system described in this post glosses over certain issues which would be problematic in a real application, and no discussion involving distributed systems would be complete without addressing some of the ways in which they can fail.
We expect our system to finish processing each event within 50 seconds. What if it doesn’t?
With the system we’ve implemented here, the most likely failures are:
-
Incomplete file processing due to reaching the Lambda invocation time limit. There might be too many counters in each file for us to process even after making improvements to our implementation and paying for more DynamoDB capacity.
-
Incomplete file processing due to a provisioned throughput exception. Our library will perform retries, but only up to a point before giving up and raising an exception.
Both timing out and raising an exception are treated as execution errors by Lambda and will result in our function being invoked again with the same event some time later (up to a certain number of retry attempts).
While the system we’ve described is idempotent—each instance uploads its current set of counter values, not counter deltas—this retry behavior can still be problematic for our system as-written: a failing invocation C might be followed by a successful invocation D, which is then followed by a successful retry of C (“lost update” problem). Unless we take steps to mitigate this, older data from C could wipe out newer data from D if our bucket uses versioning and they correspond to the same uploading instance. We can handle this by adding a per-instance event timestamp to our first table’s items and including it in our condition expression.
We could also encounter a situation where we can never catch up because the incoming data rate exceeds the maximum sustained processing rate. If this happens after we’ve already made our implementation more efficient and increased our provisioned capacity, we should consider adjusting our schema (i.e., so that we may use BatchWriteItem operations on our first table) and/or rethink our system’s design. (We also control the systems producing this data, so nothing is set in stone!)
A word on latency
We listed reaction times earlier in our cost estimate, based on the following system latency formula:
| \(L\) | latency |
| \(u\) | time until upload |
| \(d_1\) | delivery time (first lambda function) |
| \(p_1\) | processing time (first lambda function) |
| \(d_2\) | delivery time (second lambda function) |
| \(p_2\) | processing time (second lambda function) |
We estimated our system’s reaction time by ignoring time until upload, assuming minimal delivery time values (0-0.1s), the same processing time values (50s), and a small fudge factor, giving a range of 0.1-51s. This ignores two important details: (1) concurrency limits for Lambda (100 concurrent executions in each account region by default) and (2) the sharding of our DynamoDB stream (maximum stream reader invocation concurrency is the number of shards in the stream).
Item (2) is most problematic in our system—compared to our first Lambda function, our second function will be invoked more frequently (smaller batches of counter updates) and with less concurrency (limited by number of stream shards); therefore, the assumption we made in our cost estimate about “similar function characteristics” was flawed.
Experimentation reveals that even with tuning and implementation improvements, our system’s best total latency is 64s (with 100 file uploads of 100 counters every 60s). If this is due to our second Lambda function taking more than 60s to finish processing all events, this is the “never catch up” situation described earlier. Updating our second Lambda function to use BatchWriteItem instead of UpdateItem requires no schema change and greatly improves performance, bringing total system latency back in line with our expectations.
Final words
While no tool is right for every job, I had fun writing this post and I look forward to using Lambda more often in situations where it makes sense to do so. I hope you found this discussion and example interesting!
Exercises for the reader:
-
Improve the efficiency and implementation of both Lambda functions. Try using
multiprocessingin the first (but note thatPoolandQueuewon’t work) and implement exponential backoff/retry for provisioned throughput exception handling. UseBatchWriteItemin the second Lambda function. -
Implement a third Lambda function using the recipes in this post which watches our second DynamoDB table for per-counter updates, and which emits the summed values for all of a particular day’s counters back to S3 when any counter’s summed value changes.
Want to learn more about AdRoll? Roll with Us!