Querying Data in Amazon S3 Directly with User-Space Page Fault Handling
tl;dr AdRoll’s real-time bidding system produces tens of billions events daily. We store these events in TrailDBs, a fast embedded database that we recently open-sourced. By leveraging a cool new feature in the Linux kernel, you can now query TrailDBs directly in Amazon S3 without having to store the database locally, like here:
Tens of Trillions of Events in Amazon S3
We have been very happy with our data processing pipeline, built on top of Docker, Luigi, Spot Instances, and Amazon S3. It allows us to process hundreds of terabytes of data stored in TrailDBs cost-efficiently with low operational overhead.
A typical job at AdRoll downloads a set of TrailDB shards from S3, processes them, and pushes results back to S3. This model works fine for batch jobs that need to query a large amount of data, similar to a full table scan in RDBMS. Over time, our TrailDB shards have grown in size (more rows) and they include a wider variety of information (more columns). Consequently, an increasing number of queries need to access only a subset of rows and columns.
Having to download gigabytes of unneeded data to find the proverbial needle in a haystack, expressed as a highly selective query, is quite expensive. A more efficient solution would download only the specific bytes that matter for the query. Traditional data warehouses address this issue by carefully managing both storage and query optimization. In contrast, our TrailDB-on-AWS architecture unbundles storage from querying for ease of scalability and operation, similar to many other big data systems.
However, we can still leverage a traditional database technique to solve the problem, namely page management. Instead of downloading a full shard, we can fetch only the pages that are required to execute the query.
User-Space Page Fault Handling
Cache and page managers are very non-trivial subsystems of modern databases. The topic is an inherently complex one but it is further complicated by the complex interplay between the kernel and the database. After all, the kernel has a very non-trivial subsystem of its own for page management that doesn’t always work in perfect harmony with its database counterpart.
It is a valid question whether the database even needs a virtual memory system of its own, instead of just letting the kernel take care of the job. In practice, it is not easy to make the kernel-managed paging perform as well as a custom subsystem given how much the database knows about the data and its access patterns in contrast to the kernel.
Enter a very promising new feature in the Linux kernel, user-space page fault handling. This feature allows a user-space application, such as the TrailDB library, to handle page faults, that is, a certain piece of data being missing from the process’ address space, as it best sees fit. In particular, this feature allows us to fetch page-size (4KB) chunks of data from S3 with practically no impact to the existing codebase.
While user-space page fault handling might not be flexible enough yet to replace Postgres’ venerable page management subsystem, it allowed us to implement this key piece of functionality in TrailDB in less than 2000 lines of code while working harmoniously with the kernel. As demonstrated by this case, it is extremely powerful to be able to embed application-specific policies in kernel mechanisms that take care of heavy lifting such as page fault handling, and, in other cases, file systems, and packet processing.
The API for user-space page fault handling is surprisingly straightforward. If you are curious, you can try userfaultfd() yourself by following this hello world tutorial.
TrailDB External Data Architecture
The solution implemented in TrailDB is fully generic and allows data to be fetched from any source, not just Amazon S3. The block servers that handle interfacing with the data sources are pluggable and implemented outside the TrailDB library, so they can be conveniently implemented in any programming language.
Interfacing with S3 is implemented by a block server written in Go, traildb-s3-server. In the diagram below, this is the “server process.” The TrailDB application, “client process,” communicates with the server using simple requests sent over TCP.
The purple box is an unmodified application using the TrailDB library. The blue boxes are responsible for paging and caching. The yellow box is an external data source, in our case Amazon S3.
Let’s walk through a page fault situation, that is, what happens when TrailDB tries to access a piece of external data like s3://traildb.io/data/wikipedia-small.tdb that is managed by the user-space page fault handler:
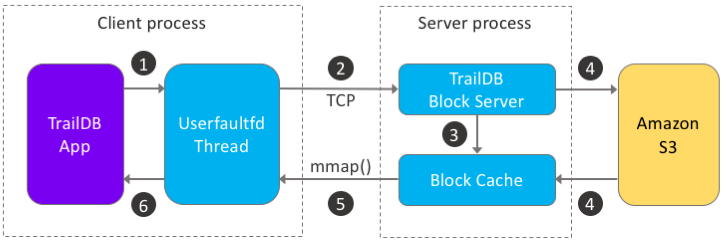
1. Page fault generated
If tdb_open() is called with a non-local URL, e.g. s3://, memory regions that are normally memory-mapped with a file are mapped as MAP_ANONYMOUS and the region is registered to the user-space page fault handler.
When the region is accessed by TrailDB as usual, a page fault is generated which blocks the app. Instead of the page fault being handled by the kernel, it sends a message to the userfaultfd file descriptor indicating what address was requested.
source tdb_external.c
2. User-space page fault handler triggered
When tdb_open() was called with a non-local URL, also a separate thread was launched to handle page faults. The thread uses poll() to wait for incoming messages in the userfaultfd file descriptor.
When a message is received, the virtual address requested is translated to an offset in the TrailDB file. Next, the handler checks if the offset corresponds to the latest block received from the server. If it does, we already have the required data which can be copied back to the app.
source tdb_external_pagefault.c
If the offset doesn’t resolve to the latest block, we must request a new block from the block server. A simple message is prepared which contains the URL of the TrailDB, an offset, and the minimum number of bytes requested, typically 4KB. This message is then sent over a TCP connection to the server.
source tdb_external_comm.c
3. Block server handles the request
The block server is expected to return bytes at the requested offset.
For efficiency reasons, our traildb-s3-server caches blocks received from S3 locally. When a request is received, first we need to check if the block exists in the local cache, possibly as a sub-range of a previous cached larger block.
source blockcache.go.
If the block is found, the server sends a response that includes a local path and an offset where the client can find the requested block. Currently we assume that both the client and the server share a common filesystem.
source s3tdb.go.
4. Block server fetches a block from S3
If the block is not found, we must fetch it from its original source, in this case from Amazon S3. This is accomplished using the standard AWS SDK for Go, which, besides downloading data, handles authentication transparently, in our case using an instance-specific IAM role.
S3 supports standard HTTP range requests, which allows us to request an exact range of bytes from S3. Since there is quite a high constant overhead and a monetary price associated to each GET request in S3, it makes sense to request a larger block instead of the single 4KB page that was originally requested by the client. You can read more about the effect of the block size below.
After a successful download, the block is added to the cache, and a response is sent to the client as in Step 3.
source s3tdb.go.
5. The requested block is memory-mapped by the client
The page fault handler receives a path and an offset to the requested block from the server. The block is memory mapped by the handler.
source tdb_external_pagefault.c
6. The requested page is delivered
The page fault handler thread uses UDDFIO_COPY to copy the requested page back to the app’s address space atomically. Once this call finishes, the app thread unblocks and it proceeds to process data as usual.
source tdb_external_pagefault.c
Performance
As described above, handling a single page fault may require up to six steps which involve a separate thread, a TCP connection, a server, and an HTTPS request to S3. Is this going to be too slow for realistic workloads?
Below we have benchmarked the S3-direct solution versus the baseline approach that involves downloading the full TrailDB file first to a local disk. The test data is a 100MB snapshot of Wikipedia edit history, as seen in the TrailDB tutorial. This TrailDB contains 6.3M trails. The benchmarks were performed on an r3.8xlarge EC2 instance in the same region where the data is located in S3.
Sequential Access
First, consider a simple case where you want to access the first X trails in the TrailDB. In the chart below the green line shows the constant cost of the baseline: it takes about 1.6 seconds to download the full TrailDB. After downloading it, there is practically no cost for accessing the first 0-2000 trails.
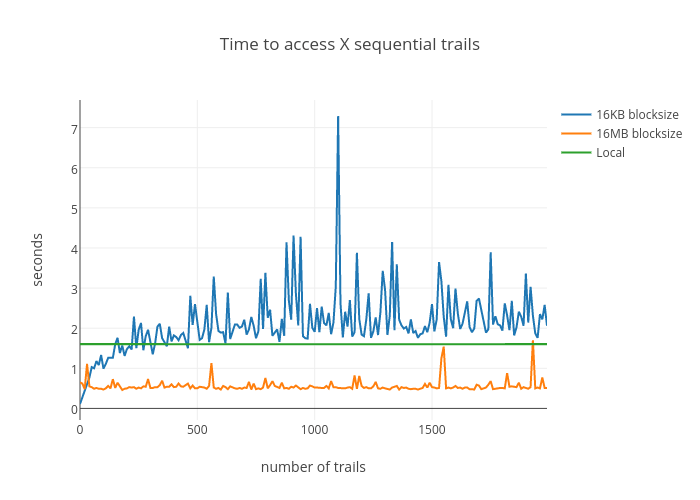
The orange line shows the cost for performing the same operation using S3 directly with a 16MB block size. Accessing the first 0-2000 trails involves downloading a single 16MB block, which takes about 500ms.
The blue line shows the cost for using S3 directly with a 16KB block size. The small block size yields the lowest latency to the first results: You can get results for the first 0-10 trails in about 100ms, which is a 16x speedup compared to the baseline! However, the more trails are processed the more small blocks need to be fetched. The overhead adds up so that at about 200 trails it is cheaper to use the baseline approach instead.
Random Access
It is expected that sequential access favors large block sizes. However, the original needle in a haystack question is more about random access.
Like above, the baseline approach first downloads the full TrailDB and then access X trails randomly. Again, the cost to download dominates the total cost since a small 100MB TrailDB fits in memory easily.
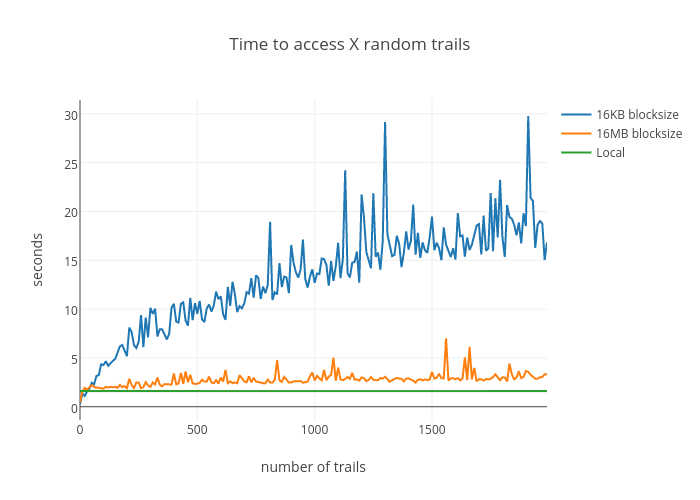
The break-even point is about 20-30 trails. If you need to access fewer trails than this, it is faster to use S3 directly. Note that the break-even point heavily depends on the size of the TrailDB. With many of our production TrailDBs that can exceed a terabyte in size, the break-even point is much higher.
Another thing to note above is how close the orange 16MB line is to the baseline. The overhead of S3 direct is about 10-15%.
Overhead of User-Space Page Fault Handling
If we extended the X axis above to cover all the 6.3M trails, all blocks of the test TrailDB would end up being cached locally. After this, there is no need to download anything from S3 and the difference between the S3 direct approach and the baseline should equal to just the overhead of user-space page fault handling.
As mentioned in Step 2 above, if the latest block received contains the data we need, we can skip the following Steps 2-5 which involve a context switch to another process and sending a message over TCP, amongst other things. Hence, the fewer blocks we need to request, the less overhead there is.
We evaluate this overhead of the fully cached case as a function of the block size versus the blue baseline. The operation performed is a full scan over all the trails:
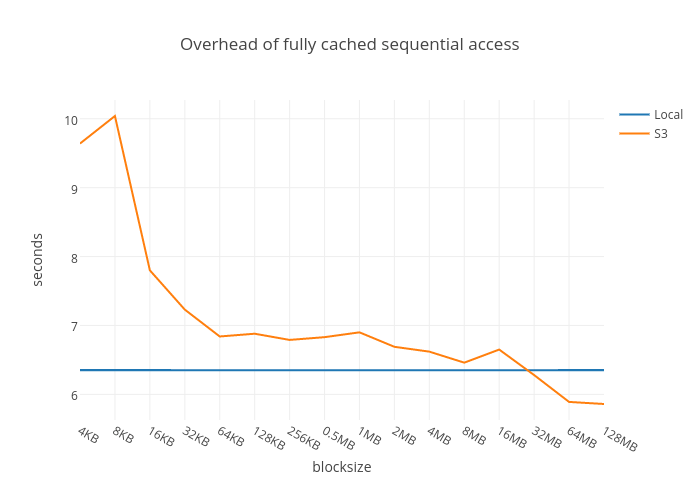
With a small block size, 4-16KB, practically every page fault involves all the steps, except S3 download in this case. With a larger block size, the overhead reduces to 10-15% what we saw above. Interestingly, when the block size approaches the size of the full DB, S3 direct becomes faster than the baseline. This is caused by the extra overhead of having to launch a separate process to download the data in the baseline case.
Overall, user-space page fault handling has a surprisingly low overhead compared to page fault handling in the kernel. The 10-15% overhead shown above is caused by our particular implementation, not userfaultfd() per se. This could be optimized further if needed.
S3 Bandwidth
Of course, fetching data from S3 is by far the most expensive part of the process. We want to evaluate if our way of downloading data from S3 performs well.
We leverage the standard AWS SDK for Go for downloading, which should be reasonably performant. It is widely known that aggregate S3 bandwidth increases with more concurrent downloaders. The current implementation treats each tdb handle as a separate thread both on the client and the server side. Hence, you should be able to increase bandwidth by either opening multiple tdb handles to a single TrailDB and sharding it by row, or by handling multiple TrailDBs in parallel.
The benchmark supports this hypothesis:
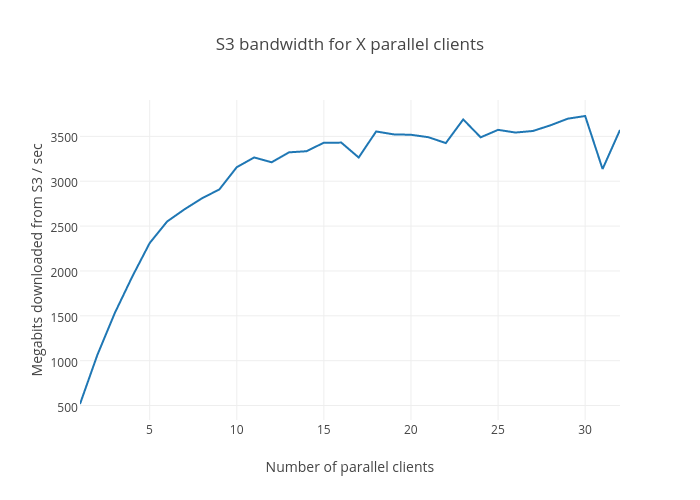
You can nearly saturate the S3 bandwidth on a single instance with about 20 parallel handles. Based on our previous findings, the maximum bandwidth achievable between a single EC2 instance and S3 is about 4Gbit/sec. In the above case, we use a single SSD as a backing store so the 3.5Gbit/sec peak may be bottlenecked by the SATA interface. In other words, using S3 directly can provide you the same bandwidth as a local SSD.
Conclusion
The benchmarks show that using S3 directly with user-space page fault handling is an excellent solution to our original problem with highly selective queries. We were positively surprised that the overhead of this solution is low even for the full sequential scan case, which suggests that all workloads could benefit from this solution.
Finding a needle in a haystack is a perfect exemplar for using S3 directly. It turns out this approach has a number of other benefits as well:
- Infinitely lower time to first results, depending on the TrailDB size. This is especially useful for ad hoc queries, which can be interrupted if the first results are not satisfactory.
- Makes it possible to process TrailDBs that are larger than local disk space. This is a potential killer feature, since this allows you to use instance types with little or no local disk space which in turn means more opportunities for cost optimization.
- The separate block server further clarifies the separation between the storage and the query layer, opening up interesting new use cases. The block server can be developed quickly outside of the core TrailDB codebase.
Future work includes dynamic block sizes, smarter prefetching and eviction policies for the block server, and support for new data sources besides Amazon S3. Contributions are welcome!
Give it a try!
Although this work is not merged to the TrailDB master branch as of writing of this blog article, you should be able to give it a try easily:
-
Make sure that your kernel supports
userfaultfd. You need Linux kernel 4.3 or newer withUSERFAULTFDenabled. With many distributions, you can check this by runninggrep USERFAULTFD /boot/config*which should returnCONFIG_USERFAULTFD=yif the feature is enabled in your kernel. For instance, Ubuntu Yakkety Yak (16.10) works out of the box. -
Git clone the
userfaultbranch of TrailDB:git clone -b userfault https://github.com/tuulos/traildband follow the installation instructions. -
Git clone the
traildb-s3-serve:git clone https://github.com/tuulos/traildb-s3-serverand rungo buildas usual.
After this, you can start ./traildb-s3-server and use e.g. the tdb command line tool to access data directly from S3:
tdb dump -i s3://my-bucket/my.tdb
If you have any trouble with installation or you have any other questions or feedback, please join us at our TrailDB Gitter channel.