Streaming Petabytes of Data in Realtime with Kinesis
AdRoll’s real-time data pipeline drives many systems crucial to our business. These systems inform the decisions made by our real-time bidding infrastructure in response to the tens of billions of daily requests we receive from ad exchanges. They also refresh our predictive models, guard against overspend, and deliver up to the minute campaign metrics through our dashboard. To function properly these systems need to maintain 100% uptime while inhaling about 1.3 petabytes of data per month across 5 regions worldwide.
We’ve found that improving real-time data recency directly correlates with improved performance and is an enabler for future features and products. As such, we recently found ourselves motivated to overhaul our real-time pipeline in an effort to reduce end to end latency as much as possible. By leveraging Amazon’s scalable data streaming service Kinesis we were able to drop our real-time pipeline’s processing latency from 10 minutes to just under 3 seconds (while simultaneously cutting costs and improving system stability!).
Our pipeline involves feeding event logs generated by our real-time bidders and ad-servers into a set of Storm topologies and a few other proprietary applications which do our real-time processing. Originally, we ingested data by reading log files rotated to S3 every few minutes from each bidder and ad-server. But this mode of ingestion caused a tension between S3 performance and data processing latency - flushing logs more often improves recency but yields a larger number of smaller log files, which degrades list and read performance. We found that in practice we were bounded by a 10 minute average processing delay with this setup.

To break the 10 minute recency barrier we needed a continuous data streaming service. But not just any off the shelf solution would suffice. Whatever we chose would have to be able to reliably handle our volume while providing redundancy/fault tolerance. Additionally, we would need this service deployed near each of our geographically distributed data centers. The motivation here is to minimize data loss in the event of a machine failure – we wouldn’t be able to offload logs as frequently or as reliably with transcontinental network calls involved. Presumably, once in our streaming service, data will be more durable, so our real-time processing applications (which live in a single region) would be better suited to stream logs across oceans.
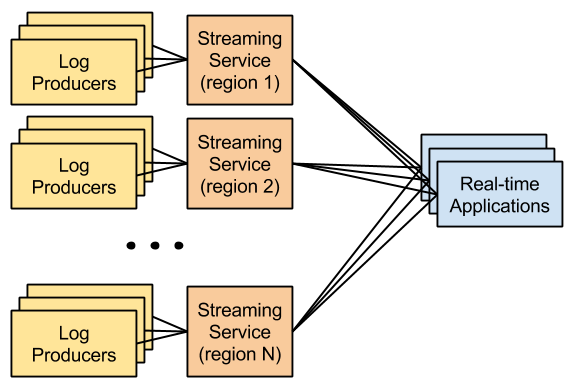
Initially we explored Kafka but we found it difficult to configure properly and it fell over every time we tried to scale. We kept running into issues with tasks like setting up cross datacenter mirroring and allocating the appropriate amount of disk space per topic. Eventually we started looking for an easier to manage solution.
Enter Kinesis. Very similar to Kafka, Kinesis is a partitioned streaming service. In Kinesis data producers push small data blobs called records into streams which are broken into partitions called shards. Kinesis has built in redundancy and is arbitrarily scalable by design so it can handle our volume. And it’s an AWS service so we get streaming locally to the regions where our log producers reside for free because all of our infrastructure already lives on AWS. Also, it’s a managed service so don’t have to worry about configuring and tuning and we won’t be losing any sleep from ops work!
We were able to get up and running on Kinesis fairly quickly with some plug and play libraries. On our log producers, which are written in Erlang, we used Kinetic, an open source Erlang Kinesis client developed here at AdRoll. Kinetic runs on a logging process which lives in each of our real-time bidders and ad-servers and handles about 5,000 logs per second (per machine). We designed this process to flush data in small batches which are formed by concatenating logs until either Kinesis’s 1MB record size limit is reached or 1 second has passed since the last flush. This allows us to minimize put record requests which are expensive due to network calls …and the fact that we’re literally billed by Amazon for them.
On the Kinesis consumer side, we connected our Storm topologies to Kinesis by forking Amazon’s Kinesis storm spout. For those unfamiliar with Storm, spouts are components which ingest data from outside sources and send it to other Storm components to be processed. Out of the box we found the spout streamed data too slowly because polling from Kinesis was tightly coupled with Storm’s requests for the spout to emit data. This is shown in the (simplified) snippet of code from Amazon’s library below:
// poll records for a Kinesis stream shard
public class KinesisShardGetter {
...
AmazonKinesisClient kinesisClient;
...
// read and emit Kinesis records
public List<Record> getNext(int numRecords) {
GetRecordsRequest request = new GetRecordsRequest();
request.setLimit(numRecords);
GetRecordsResult result = kinesisClient.getRecords(request);
return result.getRecords();
}
...
}In the vanilla library, Storm requests data from KinesisShardGetter objects via getNext(...) and each of these requests kicks off a slow, blocking network call to Kinesis made by the kinesisClient. This doesn’t scale well and a single spout will quickly reach its network bounded throughput cap even when consuming from a small number of shards. To make the spout more performant we wrote our own KinesisShardGetter shown (simplified) below.
// poll and buffer records for a Kinesis stream shard
public class KinesisAsyncShardGetter extends KinesisShardGetter {
...
AmazonKinesisAsyncClient kinesisClient;
final ConcurrentLinkedQueue<Record> recordsQueue;
...
// read Kinesis records
public void readRecords() {
final GetRecordsRequest request = new GetRecordsRequest();
kinesisClient.getRecordsAsync(request, new AsyncHandler<GetRecordsRequest, GetRecordsResult>() {
@Override
public void onSuccess(GetRecordsRequest request, GetRecordsResult result) {
recordsQueue.addAll(result.getRecords());
readRecords();
}
...
}
}
...
// emit Kinesis records
@Override
public List<Record> getNext(int numRecords) {
List<Record> records = new ArrayList<>();
for (int i = 0; i < numRecords; i++) {
if (!recordsQueue.isEmpty()) {
records.add(recordsQueue.pop());
} else { break; }
}
return records;
}
...
}To avoid a blocking Kinesis network call with each getNext(...) we asynchronously poll and buffer data from Kinesis in a background thread via readRecords(). This way we need only recordsQueue.pop() to emit data into Storm from memory. This allowed us to increase the spout’s throughput to the point where we were bounded by data preprocessing instead of network latency (which was around a 10x speed boost for us).
The final deployment hurdle we had to clear was setting up some Kinesis stream management tooling/automation – namely we wanted to be able to quickly and easily create or scale all of our streams across all our AWS regions. We tried using an existing AWS labs tool but it seemed that it’s requests would rarely succeed due to poor error handling. We ended up just writing our own.
Programatically creating streams was a fairly straight forward process but very slow (it takes around 30 minutes to set up all our streams in serial). We made sure to thread create requests such that we were hitting the 5 simultaneous Kinesis stream operations per account limit.
Scaling streams was a bit of a headache because the current API makes it a very manual process. For some context, each Kinesis stream has a hash key space which is broken into sections, one for each shard. Each put request is given a random value in the stream’s hash key space to determine which shard the request will be sent to. Typically all shards own an equal slice of the hash key space so requests will be distributed evenly across all shards.
Ideally streams would be scaled by a single API call specifying a stream and a target number of shards and Amazon would handle splitting the hash key space into new, evenly sized sections. However, in the current API you are required to split and merge sections of the hash key space manually, each split and merge operation being a separate request. Moreover you need to specify the actual point in the hash key space where you want to draw new split boundaries. Properly adding a single shard to a stream with two shards takes three distinct requests! For example, given a stream with two shards owning sections [1-15], [16-30] of hash key space [1-30], to add a new shard – yielding sections [1,10], [11, 20], [21,30] – you would need to:
- Split shard
[1,15]at 10, into shards[1,10]and[11, 15]- Split shard
[16,30]at 20, into shards[16,20]and[21, 30]- Merge shards
[11,15]and[16,20]into new shard[11,20]
…I suggest avoiding scaling between relatively prime numbers of shards (stick to powers of two).
Annoyingly, split or merge requests involving unrelated shards can’t be run at the same time on the same stream. So each operation must be performed in serial and scaling a stream is very slow. Again, we made sure to thread our scaling logic to operate on multiple streams simultaneously in the event that we needed to quickly respond to a global traffic increase.
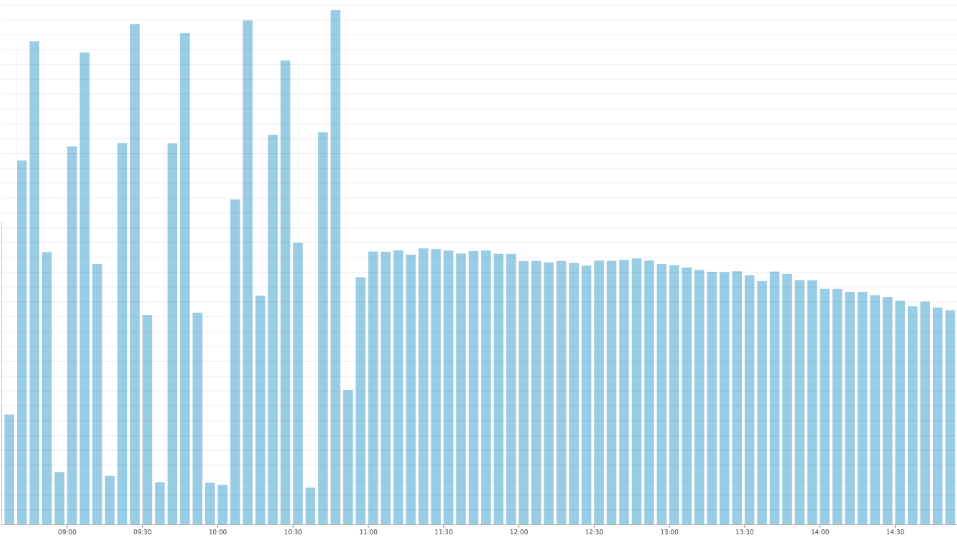
Eventually we got all of the migration details sorted out, and we hit the switch to turn on Kinesis. Immediately saw our event processing latency drop from 10 minutes to just under 3 seconds. Also, continuously streaming data smoothed out a few previously bursty workloads (can you spot the Kinesis pipeline release from the graph below of our DynamoDB writes?). This improved system stability and allowed us to cut our costs nearly in half for managed services that bill based on provisioned throughput such as DynamoDB. These savings actually more than paid for the cost of using Kinesis!
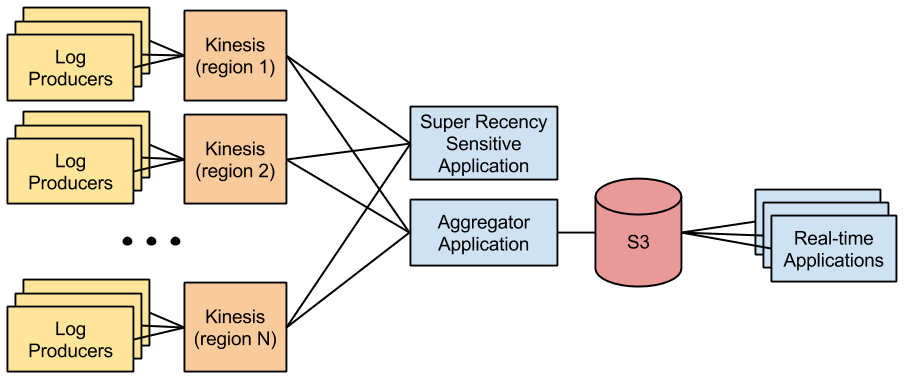
We ran into one fairly painful Kinesis service constraint though. The scale of each shard in Kinesis is based on throughput. Each shard provides a maximum write capacity of 1MB/s and a maximum read capacity of 2MB/s. This means that unless you overprovision or use multiple layers of streams you are limited to having two distinct real-time applications consuming from a Kinesis stream at any given time. Because we could potentially have around 10 real-time applications trying to consume from the same Kinesis stream we decided not to try to expose our real-time data directly from Kinesis.
In the past S3 had worked well for serving data to many concurrent consumers but it had become a performance bottleneck because we were writing out a separate log file for each of our 500+ log producers. Once we had Kinesis, however, we were able to write an application which aggregates logs from all of our data producers in a single location – allowing us to flush all logs to S3 in a single file. By doing this we can flush much more frequently and therefore expose much fresher data to all of our real-time applications without sacrificing S3 performance. By using this Kinesis to S3 architecture we were able to achieve an end to end latency of about 30 seconds for all real-time applications. Also the aggregator application only takes up one Kinesis consumer application slot so we were able to have one other application which was particularly sensitive to recency connect directly to Kinesis and enjoy the aforementioned 3 second latency.
Overhauling our data pipeline with Kinesis ended up being very fruitful and relatively painless. We were able to expose massive recency gains to our entire real-time data pipeline while at the same time improving system stability and cutting costs.
At AdRoll we’re looking for ways to improve our backend systems. If you have some ideas or have been itching to work with huge amounts of data, let us know!