Bulk Loading Multiple Tables
AdRoll’s customer dashboard is powered by our HBase cluster, populated using both Storm and Hadoop MapReduce. Using Storm allows us to provide real-time statistics to our users, while Hadoop gives us the accuracy guarantees needed for billing. Throughout the day, Storm emits a steady stream of writes to HBase. Our MapReduce jobs however, run once a day over the previous day’s data. This generates a huge spike in write traffic that can drastically slow down, if not render the entire cluster unresponsive. To counteract this, we switched to having our MapReduce jobs bulk load, skipping the write path entirely and saving both CPU and network IO. Unfortunately, we could not use the built-in bulk loading tools because of our non-standard use case.
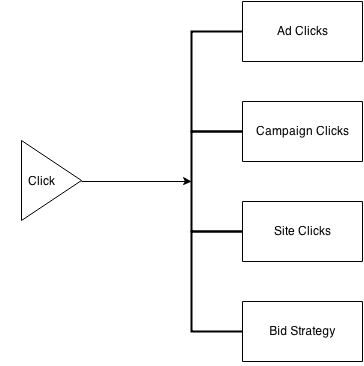
Each type of event we see is demultiplexed into a write for one or more tables. For example, a click event might lead to incrementing a counter based on which ad and campaign generated the click. For bidding purposes, we may also want to keep track of which bidding strategy was used and which site the ad was placed.
Unfortunately, with the way HFileOutputFormat is written, there was no way to do what we wanted without running over the same input multiple times. This is because HFileOutputFormat can only generate output for one table at a time. The amount of new data AdRoll collects and generates (on the order of 25TB/day) makes this a very unattractive, if not untenable option. Luckily, we have access to the source code so it was fairly painless to subclass the output format and add the ability to generate HFiles for multiple tables in one pass.
Before we dive into the technical details, we need to understand at a high level how HFileOutputFormat.configureIncrementalLoad() works. Cloudera has a great overview of bulk loading – we mostly care about section 2 copied below.
The job [Mapper] will need to emit the row key as the Key, and either a KeyValue, a Put, or a Delete as the Value. The Reducer is handled by HBase; you configure it using HFileOutputFormat.configureIncrementalLoad() and it does the following:
- Inspects the table to configure a total order partitioner
- Uploads the partitions file to the cluster and adds it to the DistributedCache
- Sets the number of reduce tasks to match the current number of regions
- Sets the output key/value class to match HFileOutputFormat’s requirements
- Sets the reducer up to perform the appropriate sorting (either KeyValueSortReducer or PutSortReducer)
At this stage, one HFile will be created per region in the output folder.
Our multi-table HFileOutputFormat (source) is going to do exactly this, but demultiplex each key into the appropriate HFile depending on destination table. The convention we have adopted is for each row key to be prepended with the table name. Colons are not legal in HBase table names, so they are safe to be used as separators. Step 1 from above then changes a little bit, but the general idea is to get each region start key and prepend the table name to it.
partition_keys = []
for table_name in tables:
start_keys = get_region_start_key(table_name)
for start_key in start_keys:
partition_key.append(table_name + ':' + start_key)
end
end
configure_total_order_partitioner(partition_keys)Step 3 will set the number of reduce tasks to the total number of regions across all tables. The actual HFile demultiplexing happens in the output format RecordWriter (lines 292-304 and 322). Instead of just writing to the output path, we separate out the table name and the row key, then write each table’s HFiles into it’s own folder. To use our new output format, all we have to do is change the mapper to emit <table>:<row key> instead of just <row key>.
The standard usage of HFileOutputFormat doesn’t allow any work to be done in the reduce step, as configureIncrementalLoad will set the reducer to be either KeyValueSortReducer or PutSortReducer. If we need to do work in the reduce step, we have two options. The first option is to have a two-step MapReduce job. The first reducer writes to a sequence file, which the second map reads and emits into a sorting reducer configured by HFileOutputFormat. The second option is a bit more efficient as it does all of the necessary work in one reducer. If we take a look at what the sorting reducers are doing, we see that all it does is take the KeyValues and emit them in sorted order. It’s easy then, to modify our reducer to do some useful work combining KeyValues, then sort and emit all in one step.
public void reduce(ImmutableBytesWritable kw, Iterable<Writable> values, Context context) {
List<KeyValue> kvs = someUsefulWork(kw, values);
TreeSet<KeyValue> map = new TreeSet<KeyValue>(KeyValue.COMPARATOR);
for (KeyValue kv: kvs) {
map.add(kv.clone());
}
// Write out the values in order
for (KeyValue kv : map) {
context.write(kw, kv);
}
}That’s all there is to it! With these simple modifications, AdRoll is able to efficiently process and load large amounts of data into our HBase cluster. We are free to denormalize our data as needed, without worrying about many of the associated costs.