trck: querying discrete time series with state machines
Last year we released TrailDB, a library we use extensively at AdRoll to efficiently store event data. Today we’re open sourcing trck, a query engine complementary to TrailDB that we use to analyze trillions of discrete events in TrailDBs every day.
As you may remember, the TrailDB data schema is very simple:
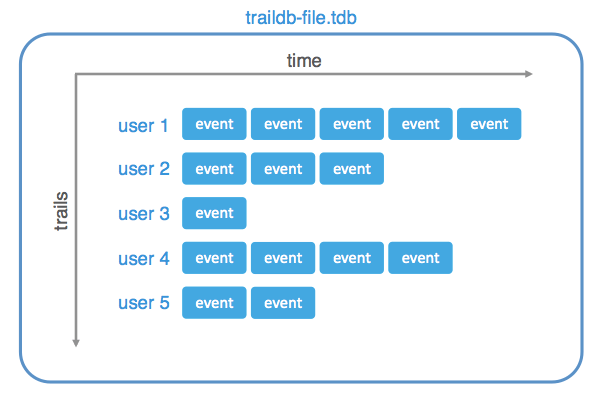
Every user (or “trail”) has a sequence of timestamped events associated with it. Every event has a number of fields, and the set of fields is fixed per TrailDB.
For example, a dataset of Wikipedia edits may contain a user’s IP address and page title as fields:
# tdb dump -j -i wikipedia-history-small.tdb | head
{"uuid": "86f7f07096e5a9f01509b2b2e9380000", "time": "1152738820", "user": "", "ip": "81.152.155.52", "title": "ZZZap!"}
{"uuid": "86f7f07096e5a9f01509b2b2e9380000", "time": "1152739029", "user": "", "ip": "81.152.155.52", "title": "ZZZap!"}
{"uuid": "86f7f07096e5a9f01509b2b2e9380000", "time": "1152739044", "user": "", "ip": "81.152.155.52", "title": "ZZZap!"}
{"uuid": "86f7f07096e5a9f01509b2b2e9380000", "time": "1152739092", "user": "", "ip": "81.152.155.52", "title": "ZZZap!"}
{"uuid": "86f7f07096e5a9f01509b2b2e9380000", "time": "1152739159", "user": "", "ip": "81.152.155.52", "title": "ZZZap!"}
{"uuid": "86f7f07096e5a9f01509b2b2e9380000", "time": "1152739280", "user": "", "ip": "81.152.155.52", "title": "ZZZap!"}
{"uuid": "2e0774e93410d504bc1720b8ad3d0000", "time": "1159025033", "user": "", "ip": "219.110.177.197", "title": "Ip dip"}
{"uuid": "237589722f980f576dd156a29d440000", "time": "1109300460", "user": "", "ip": "134.53.178.231", "title": "Joss sticks"}
{"uuid": "c0ced428660ed821de06446f10720000", "time": "1294656212", "user": "", "ip": "180.193.58.138", "title": "Indian Rebellion of 1857"}
{"uuid": "221aeaa8b065796bc568e026c1b60000", "time": "1273111183", "user": "", "ip": "70.111.4.54", "title": "Dwight-Englewood School"}Right now, if you want to query these data you can use Python or R bindings to TrailDB. So, if we want to count the number of user sessions in a TrailDB we could do this in Python:
import sys
import traildb
if __name__ == '__main__':
db = traildb.TrailDB(sys.argv[1])
sessions = 0
for cookie, trail in db.trails():
last_timestamp = 0
for event in trail:
if event.time >= last_timestamp + 30:
sessions += 1
last_timestamp = event.time
print sessionsHere, a user session is defined as a series of events no more than 30 minutes apart. If we run this script on a sample database from the TrailDB tutorial, it processes wikipedia-history-small.tdb in about 100 seconds on my laptop.
$ time python example.py wikipedia-history-small.tdb
1774765
real 1m40.645s
user 1m31.032s
sys 0m2.963sIt doesn’t sound like a lot, but that database is pretty tiny: it contains 6.5M events and 450K trails, and takes about 100MB on disk. We routinely use multi-gigabyte TrailDBs containing billions and trillions of events.
At large scale, Python starts to struggle to process all the data quickly enough. And it is not so much the Python interpreter itself; if you use PyPy, or even a completely different language, there is substantial overhead that comes just from decoding and marshalling event data since it is so granular.
That made us realize that it would be nice to have a way to query TrailDBs in some way that can bypass all that marshalling. After all, many queries are not so complicated to require a full-blown Turing complete language to express them. Conceptually, something like grep, awk, or a regular expression engine would do, except it has to work on structured events with fields and have a concept of time.
trck: “regular expressions” for TrailDBs
One thing to note is that many queries on event-based data have much in common. Usually you want to keep some kind of minimal state per trail (that’d be last_timestamp in the above example) and then depending on what events you see down the line, you take some kind of action, such as incrementing a session counter.
That sounds very similar to regular expressions, or, speaking more generally, finite state machines. For example, the above script can be expressed as a state machine:
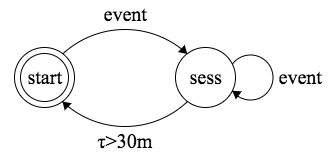
We start at the start state. Then, when we see an event in the trail, we transfer to the sess state and then on any following event, we keep coming back to sess. If we sit in sess for 30 minutes and nothing happens, we transfer back to start (and increment session counter).
And that’s what our small query language called trck does: you can express your query as a state machine, with some actions, like incrementing a counter, attached to edges.
start ->
receive
* -> sess
sess ->
receive
* -> sess
after 30m -> yield $count, startThen we can easily compile this to C code that works with TrailDB directly. If we save the above snippet as wikipedia_example.tr, call the trck compiler to produce a binary, and then run it on wikipedia-history-small.tdb:
$ ./bin/trck -c wikipedia_example.tr
Compiling wikipedia_example3.tr
Produced binary in matcher-traildb in 0.54 seconds with clang-omp[openmp]
$ time ./matcher-traildb wikipedia-history-small.tdb 2>/dev/null
{ "$count": 1774765 }
real 0m0.813s
user 0m2.819s
sys 0m0.179sNote that the evaluation of a state machine can be also trivially parallelized, as there are almost no data dependencies between state machines for different users. The trck compiler employs OpenMP for that.
As a result, this example produces the same result as the Python script, except it runs on wikipedia-history-small.tdb in about 800ms, or 100x faster. And if you run it on a much larger dataset wikipedia-history.tdb that contains the full edit log of Wikipedia for fifteen years (5GB, 600M events), it takes about 90 seconds on my laptop and scales very well with the number of cores. On a reasonably sized 16-core EC2 instance, the same query runs in 40 seconds.
There is a lot more you can do with trck: for example, in addition to counters it supports set and multiset types. There are also nested timeouts on states and some interesting higher-level optimizations that allow it to skip parts of trails that have no chance of altering the state. Check out the README.md in the repository.
Implementation
The trck compiler front end is implemented in Python using PLY. It takes the state machine and compiles it to C code, that is then linked with the trck runtime library (written in C99), producing a static binary. It is tested on Linux and on OS X. It is now available under the MIT license on GitHub .
If you have questions, you’re welcome to join our TrailDB Gitter channel.